Elasticsearch بھاری، غیر ساختہ، اور نیم ساختی ڈیٹا کو ذخیرہ کرنے کے لیے ایک مضبوط، اچھی طرح سے پسند کیا جانے والا حل ہے۔ یہ خالصتاً ایک NoSQL ڈیٹا بیس ہے اور ڈیٹا کو ذخیرہ کرنے، ان کا نظم کرنے اور بازیافت کرنے کے لیے بالکل مختلف طریقہ استعمال کرتا ہے۔ یہ JSON فارمیٹ میں ایک دستاویز میں ڈیٹا کو ذخیرہ کرتا ہے اور ذخیرہ شدہ ڈیٹا پر مختلف کارروائیوں کو انجام دینے کے لیے باقی APIs کا استعمال کرتا ہے۔
اس بلاگ میں، ہم یہ ظاہر کریں گے:
- ڈیٹا کو ذخیرہ کرنے اور تلاش کرنے کے لیے Elasticsearch کیسے کام کرتا ہے؟
- Elasticsearch دستاویزات کیا ہیں؟
- Elasticsearch دستاویز میں ڈیٹا کو کیسے ذخیرہ کیا جائے؟
ڈیٹا کو ذخیرہ کرنے اور تلاش کرنے کے لیے Elasticsearch کیسے کام کرتا ہے؟
Elasticsearch اہم اجزاء یا درجہ بندی جو ڈیٹا کو ذخیرہ کرنے کے لیے استعمال ہوتی ہے ذیل میں درج ہے:
- دستاویز: دستاویز Elasticsearch کا اہم حصہ ہے جو ڈیٹا کو JSON فارمیٹ میں اسٹور کرتا ہے۔ پسند
- اشاریہ جات: اشاریہ جات کو اشاریہ جات کہا جاتا ہے۔ یہ دستاویزات کا مجموعہ ہے۔ ایس کیو ایل کی طرح، اسے ڈیٹا بیس کہا جاتا ہے۔
- الٹی اشاریہ جات: یہ بہت تیز فل ٹیکسٹ سرچ کو سپورٹ کرتا ہے۔ یہ لفظ کو بطور اشاریہ اور دستاویز کا نام حوالہ کے طور پر محفوظ کرتا ہے۔
Elasticsearch دستاویزات کیا ہیں؟
Elasticsearch دستاویز JSON فارمیٹ میں ڈیٹا کی اسٹوریج یونٹ ہے۔ متعلقہ ڈیٹا بیس کی طرح، دستاویز کو ایک میز یا ڈیٹا بیس کی قطار کے طور پر بھیجا جا سکتا ہے جو کچھ انڈیکس میں محفوظ ہوتا ہے۔ انڈیکس میں متعدد دستاویزات ہوسکتی ہیں اور اسے ایک ڈیٹا بیس کہا جاتا ہے جس میں متعدد میزیں ہیں۔ یہ عام طور پر ایک پیچیدہ ڈیٹا سٹرکچر کو اسٹور کرتا ہے اور ڈیٹا کو JSON فارمیٹ میں جراثیم سے پاک کرتا ہے۔
مزید برآں، ہر دستاویز میں متعدد فیلڈز شامل ہو سکتے ہیں جو کہ ' کلید: قدر ڈیٹا کو ذخیرہ کرنے کے لیے جوڑے بالکل اسی طرح جیسے کسی ٹیبل میں ایک سے زیادہ کالم یا فیلڈز ہوتے ہیں۔ پھر، ان کلیدی قدر کے جوڑوں کو دستاویز کی نقشہ سازی کا تعین کرنے کے طریقے سے ترتیب دیا جانا چاہیے۔ میپنگ پھر فیلڈ ڈیٹا جیسے ٹیکسٹ، فلوٹ، جیو پوائنٹ، ٹائم اور بہت کچھ کے مطابق دستاویز کے ڈیٹا کی قسم کی وضاحت کرتی ہے۔
Elasticsearch نے ہمیں کبھی بھی انڈیکس فیلڈ ڈھانچہ کی پہلے سے وضاحت کرنے کا پابند نہیں کیا اور دستاویزات انڈیکس میں مختلف فیلڈ ڈھانچہ رکھ سکتی ہیں۔ تاہم، اگر فیلڈ کی میپنگ کو ایک مخصوص ڈیٹا کی قسم کے لیے بیان کیا گیا ہے، تو انڈیکس میں موجود تمام Elasticsearch دستاویزات کو اسی میپنگ کی قسم کی پیروی کرنی چاہیے۔ Elasticsearch میں ڈیٹا ذخیرہ کرنے کے لیے دستاویز کے کام کو چیک کرنے کے لیے، اگلے حصے میں جائیں۔
Elasticsearch دستاویز میں ڈیٹا کو کیسے ذخیرہ کیا جائے؟
Elasticsearch میں ڈیٹا ذخیرہ کرنے کے لیے، صارف کو پہلے ایک انڈیکس بنانے کی ضرورت ہے۔ پھر، Elasticsearch دستاویز میں ڈیٹا کو ذخیرہ کرنے کے لیے فیلڈز کی وضاحت کریں۔ مظاہرے کے لیے، درج کردہ مراحل سے گزریں۔
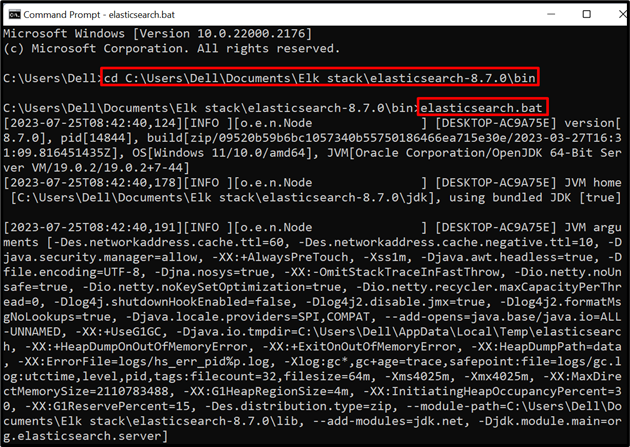
مرحلہ 1: Elasticsearch شروع کریں۔
سسٹم پر Elasticsearch ڈیٹا بیس یا انجن چلانے کے لیے، سسٹم ٹرمینل جیسے کمانڈ پرامپٹ کو لانچ کریں۔ اس کے بعد، ملاحظہ کریں ' بن 'Elasticsearch کے فولڈر کے ذریعے' سی ڈی ' کمانڈ:
سی ڈی C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
اس کے بعد، سسٹم پر ڈیٹا بیس کو چلانے کے لیے Elasticsearch کی بیچ فائل کو عمل میں لائیں:
elasticsearch.bat
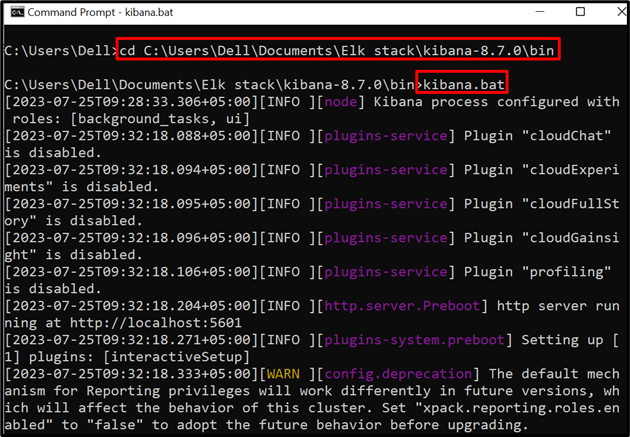
مرحلہ 2: کبانا شروع کریں۔
اگلا، سسٹم پر کبانا کو پھانسی دیں۔ ایسا کرنے کے لئے، اس کا دورہ کریں ' بن کمانڈ پرامپٹ سے فولڈر:
سی ڈی C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
اگلا، کبانا پر عمل درآمد شروع کرنے کے لیے درج ذیل کمانڈ کو چلائیں:
kibana.bat
نوٹ: اگر آپ نے سسٹم پر Elasticsearch اور Kibana کو انسٹال اور سیٹ نہیں کیا ہے، تو ہماری پوسٹس پر جائیں، اور انہیں سسٹم پر انسٹال کرنے کے لیے مرحلہ وار طریقہ کار دیکھیں۔
Elasticsearch کے لیے، ہمارے ' ونڈوز پر .zip کے ساتھ Elasticsearch کو انسٹال اور سیٹ اپ کریں۔ 'مضمون. ونڈوز پر کبانا سیٹ اپ کرنے کے لیے، ' Elasticsearch کے لیے Kibana سیٹ اپ کریں۔ 'مضمون.
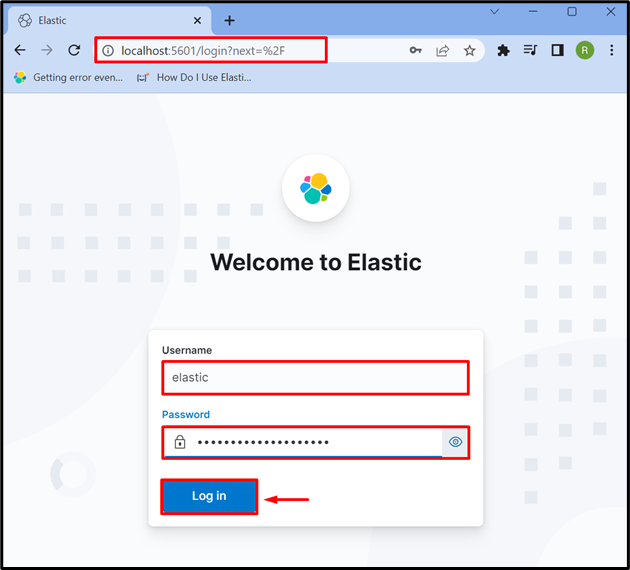
مرحلہ 3: Kibana میں لاگ ان کریں۔
سسٹم پر کبانا شروع کرنے کے بعد، کبانا کے ڈیفالٹ ایڈریس پر جائیں۔ لوکل ہوسٹ: 5601 براؤزر میں، اور Elasticsearch کے لاگ ان کی اسناد فراہم کریں جیسے کہ ' لچکدار صارف اور پاس ورڈ۔ اس کے بعد، 'دبائیں۔ لاگ ان کریں بٹن:
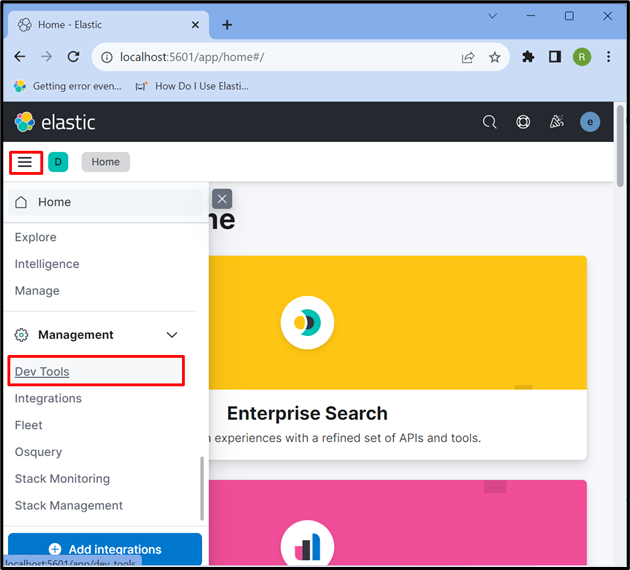
مرحلہ 4: کبانا 'دیو ٹول' کھولیں
اس کے بعد، 'پر کلک کریں تین افقی سلاخوں 'آئیکن اور کبانا کھولیں' دیو ٹول ڈیٹا کو ذخیرہ کرنے، بازیافت کرنے اور اپ ڈیٹ کرنے کے لیے APIs استعمال کرنے کے لیے:
مرحلہ 5: انڈیکس بنائیں
اب، 'کا استعمال کرتے ہوئے ایک نیا انڈیکس بنائیں ڈالیں /
آؤٹ پٹ سے پتہ چلتا ہے کہ ' ملازم کا ڈیٹا 'انڈیکس کامیابی کے ساتھ بنایا گیا ہے:
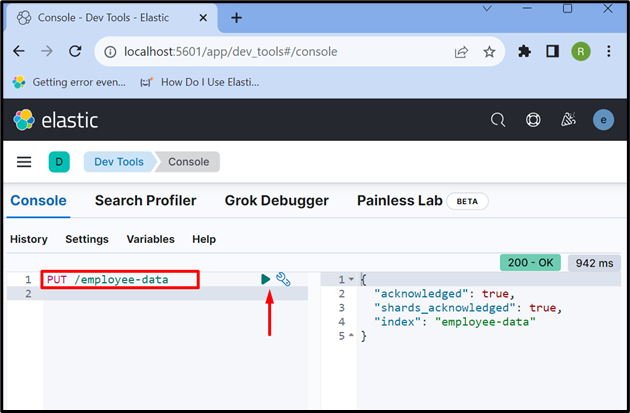
مرحلہ 6: دستاویز میں ڈیٹا داخل کریں۔
اب، استعمال کریں ' پوسٹ انڈیکس میں ڈیٹا اسٹور کرنے کے لیے API۔ درج ذیل درخواست میں، ' ملازم کا ڈیٹا 'Elasticsearch کا ایک اشاریہ ہے،' _doc 'Elasticsearch دستاویز میں ڈیٹا کو ذخیرہ کرنے کے لیے استعمال کیا جاتا ہے، اور' 1 آئی ڈی ہے:
پوسٹ / ملازم کا ڈیٹا / _doc / 1 خوبصورت{
'نام' : 'رفیعہ' ،
'DOB' : '19-نومبر-1997' ،
'ذخیرہ شدہ' :سچ
}
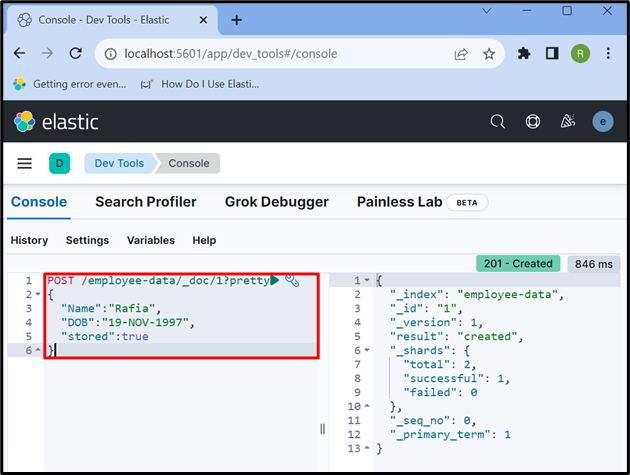
مرحلہ 7: Elasticsearch دستاویز سے ڈیٹا بازیافت کریں۔
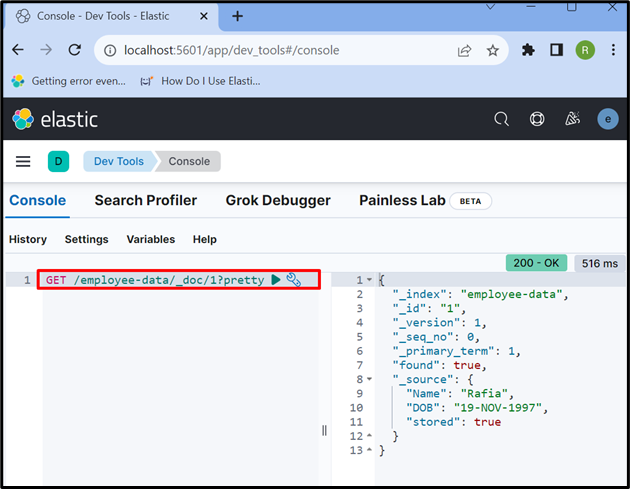
انڈیکس یا Elasticsearch دستاویز سے ڈیٹا تک رسائی حاصل کرنے کے لیے، ' حاصل کریں۔ API جیسا کہ ذیل میں استعمال کیا گیا ہے:
حاصل کریں۔ / ملازم کا ڈیٹا / _doc / 1 خوبصورت
آؤٹ پٹ سے پتہ چلتا ہے کہ ہم نے id کے ساتھ Elasticsearch دستاویز سے ڈیٹا کو کامیابی کے ساتھ نکال لیا ہے۔ 1 ”:
یہ سب Elasticsearch دستاویز کے بارے میں ہے۔
نتیجہ
Elasticsearch دستاویز عام طور پر JSON فارمیٹ میں ڈیٹا ذخیرہ کرنے کے لیے استعمال ہوتی ہے۔ متعلقہ ڈیٹا بیس کی طرح، دستاویز کو ایک قطار کے طور پر حوالہ دیا جا سکتا ہے جو کچھ انڈیکس میں ذخیرہ کیا جاتا ہے. ان اشاریہ جات میں متعدد دستاویزات ہو سکتی ہیں جیسے ڈیٹا بیس میں مختلف ٹیبلز ہوتے ہیں۔ ان دستاویزات میں متعدد فیلڈز ہیں جو کہ ' کلید: قدر ڈیٹا کو ذخیرہ کرنے کے لیے جوڑے۔ اس مضمون نے دکھایا ہے کہ Elasticsearch دستاویزات کیا ہیں اور وہ Elasticsearch میں کیسے کام کرتے ہیں۔