بعض اوقات دیا گیا ڈیٹا سیٹ کسی ایک CSV فائل میں نہیں ہوتا ہے۔ وہ سب مختلف ایکسل شیٹس پر ہیں۔ آپ پہلے ہی جان چکے ہیں کہ متعدد ڈیٹا سیٹس کے بجائے ایک ہی ڈیٹاسیٹ پر تمام کمپیوٹیشنل یا پری پروسیسنگ سرگرمیاں انجام دینا افضل ہے۔ یہ اس وقت کو کم کرتا ہے یا بچاتا ہے جو ہمیں پری پروسیسنگ کاموں پر خرچ کرنے کی ضرورت ہے۔ اس کے علاوہ، ایک ڈیٹا تجزیہ کار یا ڈیٹا سائنسدان کے طور پر، آپ اکثر اپنے آپ کو متعدد CSV فائلوں سے بھرے ہوئے پا سکتے ہیں جنہیں آپ کے دستیاب ڈیٹا کا تجزیہ یا جانچ شروع کرنے سے پہلے ضم ہونا ضروری ہے۔ دوسری طرف، یہ ہمیشہ ممکن نہیں ہے کہ تمام فائلیں ایک یا ایک ہی ڈیٹا سورس سے حاصل کی گئی ہوں اور ان کے کالم/متغیر کے نام اور ڈیٹا کا ڈھانچہ ایک جیسا ہو۔ یہ پوسٹ آپ کو ایک جیسی یا مختلف کالم کی ساخت کے ساتھ دو یا زیادہ CSV فائلوں کو یکجا کرنا سکھائے گی۔
CSV فائلوں کو کیوں جوڑیں؟
ڈیٹا سیٹ کسی مخصوص موضوع سے متعلق اقدار یا اعداد کا مجموعہ یا گروپ ہو سکتا ہے۔ مثال کے طور پر، ایک مخصوص کلاس میں ہر طالب علم کے ٹیسٹ کے نتائج ڈیٹا سیٹ کی ایک مثال ہیں۔ بڑے ڈیٹا سیٹس کے سائز کی وجہ سے، وہ اکثر مختلف زمروں کے لیے الگ الگ CSV فائلوں میں محفوظ ہوتے ہیں۔ مثال کے طور پر، اگر ہمیں کسی مخصوص بیماری کے لیے کسی مریض کا معائنہ کرنے کی ضرورت ہوتی ہے، تو ہمیں ہر جزو پر غور کرنا چاہیے، بشمول ان کی جنس، طبی ریکارڈ، عمر، بیماری کی شدت وغیرہ۔ نتیجتاً، CSV ڈیٹا کو یکجا کرنے کی ضرورت ہوتی ہے تاکہ مختلف پیش گوئوں پر اثر انداز ہو سکیں۔ پہلوؤں اس کے علاوہ، کمپیوٹیشن یا پری پروسیسنگ کے کاموں کو انجام دینے کے دوران کئی ڈیٹا سیٹس کے بجائے ایک ہی ڈیٹا سیٹ پر کام کرنا اور اس کا نظم کرنا بہتر ہے۔ یہ میموری اور دیگر کمپیوٹیشنل وسائل کو بچاتا ہے۔
ازگر میں CSV فائلوں کو کیسے جوڑیں؟
Python میں دو یا زیادہ CSV فائلوں کو یکجا کرنے کے متعدد طریقے اور طریقے ہیں۔ ذیل کے سیکشن میں، ہم CSV فائلوں کو پانڈاس ڈیٹا فریم میں یکجا کرنے کے لیے append()، concat()، اور merge() فنکشنز وغیرہ استعمال کریں گے پھر ڈیٹا فریم کو ایک CSV فائل میں تبدیل کیا جائے گا۔ ہم ایک جیسی یا متغیر کالم کی ساخت کے ساتھ متعدد CSV فائلوں کو یکجا کرنے کا طریقہ سکھائیں گے۔
طریقہ نمبر 1: CSVs کو ملتے جلتے ڈھانچے یا کالموں کے ساتھ ملانا
ہماری موجودہ ورکنگ ڈائرکٹری میں دو CSV فائلیں ہیں، 'test1' اور 'test2'۔
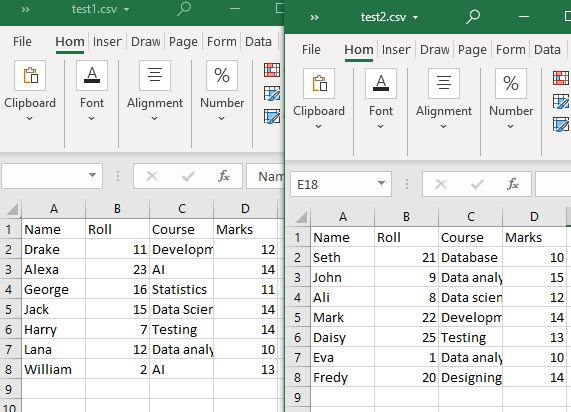
مثال نمبر 1: append() فنکشن کا استعمال
دونوں CSV فائلیں ایک ہی ساخت کی ہیں۔ glob() فنکشن اس طریقہ کار میں صرف ورکنگ ڈائرکٹری میں CSV فائلوں کی فہرست کے لیے استعمال کیا جائے گا۔ پھر ہم اپنی CSV فائلوں کو پڑھنے کے لیے 'pandas.DataFrame.append()' کا استعمال کریں گے (ایک مشترکہ ٹیبل کے ڈھانچے کے ساتھ)۔

آؤٹ پٹ:
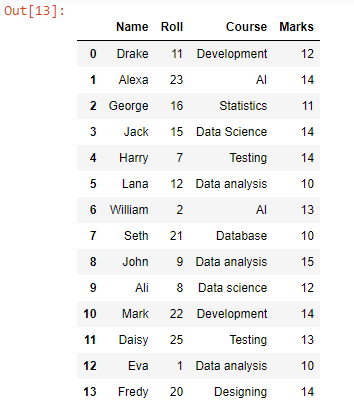
ضمیمہ فنکشن کا استعمال کرتے ہوئے، ہم نے test2.csv سے test1.csv کی ڈیٹا قطاروں کے تحت ہر ڈیٹا قطار کو شامل یا شامل کیا ہے، جیسا کہ یہ دیکھا جا سکتا ہے کہ فائل کی تمام ڈیٹا قطاریں یکجا ہو چکی ہیں۔ اس ڈیٹا فریم کو CSV میں تبدیل کرنے کے لیے، ہم to_csv() فنکشن استعمال کر سکتے ہیں۔

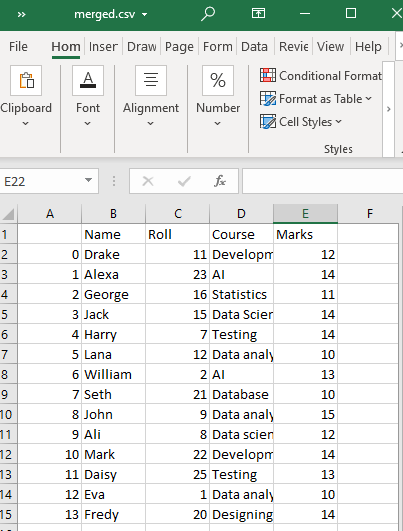
یہ ہماری ورکنگ ڈائرکٹری میں مخصوص نام کے ساتھ 'test1' اور 'test2' کی CSV فائلوں کی ایک مشترکہ CSV فائل بنائے گا، یعنی merged.csv۔
مثال نمبر 2: concat() فنکشن کا استعمال
ہم سب سے پہلے پانڈا ماڈیول درآمد کریں گے۔ نقشہ کا طریقہ ہر CSV فائل کو پڑھے گا جو ہم نے pd.read_csv() کا استعمال کرتے ہوئے پاس کیا ہے۔ ان میپڈ فائلز (CSV فائلز) کو پھر فنکشن pd.concat() کا استعمال کرتے ہوئے ڈیفالٹ کے ذریعے قطار کے محور کے ساتھ جوڑ دیا جائے گا۔ اگر ہم CSV فائلوں کو افقی طور پر جوڑنا چاہتے ہیں، تو ہم axis=1 پاس کر سکتے ہیں۔ ignore index کی وضاحت کرنا = True مشترکہ ڈیٹا فریم کے لیے مسلسل اشاریہ کی قدریں بھی بناتا ہے۔

pd.read_csv() کو concat() فنکشن کے اندر پاس کیا جاتا ہے تاکہ CSV فائلوں کو پانڈا ڈیٹا فریم میں کنکٹنیشن کے بعد پڑھا جا سکے۔
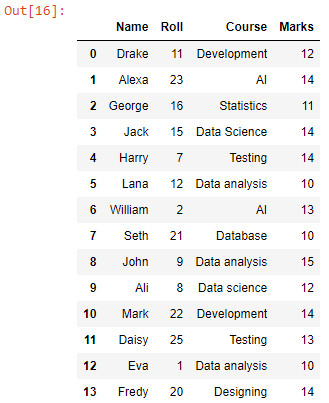
ہم نے ورکنگ ڈائرکٹری میں تمام CSV فائلوں کے مشترکہ ڈیٹا کے ساتھ ایک ڈیٹا فریم حاصل کیا ہے۔ اب، آئیے اسے CSV فائل میں تبدیل کرتے ہیں۔
ہماری مشترکہ CSV موجودہ ڈائریکٹری میں بنائی گئی ہے۔
طریقہ نمبر 2: CSVs کو مختلف ڈھانچے یا کالموں کے ساتھ ملانا
ہم نے پہلے طریقہ میں CSV فائلوں کو ایک ہی کالم اور ساخت کے ساتھ جوڑنے پر تبادلہ خیال کیا۔ اس طریقہ میں، ہم CSV فائلوں کو مختلف کالموں اور ڈھانچے کے ساتھ جوڑیں گے۔
مثال نمبر 1: merge() فنکشن کا استعمال
پانڈاس ماڈیول میں 'pandas.merge()' فنکشن دو CSV فائلوں کو یکجا کر سکتا ہے۔ ضم کرنے سے مراد صرف مشترکہ کالم یا انتساب کی بنیاد پر دو ڈیٹا سیٹس کو ایک واحد ڈیٹا سیٹ میں ملانا ہے۔
ہم شامل ہونے کے چار مختلف طریقوں سے ڈیٹا فریم کو ضم کر سکتے ہیں:
- اندرونی
- ٹھیک ہے۔
- بائیں
- بیرونی
اس قسم کے انضمام کو انجام دینے کے لیے، ہم دو CSV فائلیں استعمال کریں گے۔
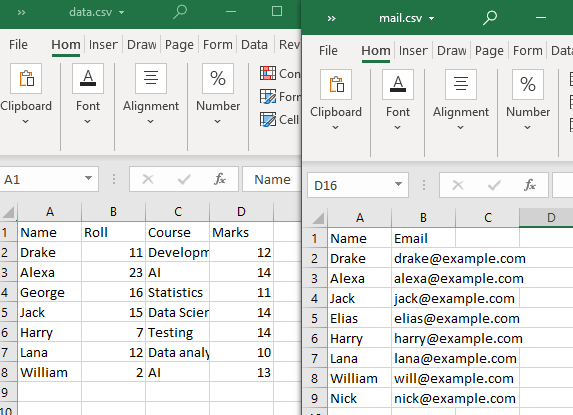
نوٹ کریں کہ کم از کم ایک انتساب یا کالم دونوں CSV فائلوں کے ذریعے شیئر کیا جانا چاہیے۔ جیسا کہ مشاہدہ کیا گیا ہے، کالم 'نام' اور اس کے کچھ اوصاف دونوں CSV فائلوں کے ذریعے مشترکہ ہیں۔
اندرونی شمولیت کا استعمال کرتے ہوئے ضم کریں۔
merge() فنکشن میں پیرامیٹر کی وضاحت کرنا how='inner' دونوں ڈیٹا فریمز کو متعین کالم کے مطابق جوڑ دے گا اور پھر ایک نیا ڈیٹا فریم فراہم کرے گا جس میں صرف دونوں اصل ڈیٹا فریموں میں ایک جیسی/ایک جیسی قدروں والی قطاریں شامل ہوں۔
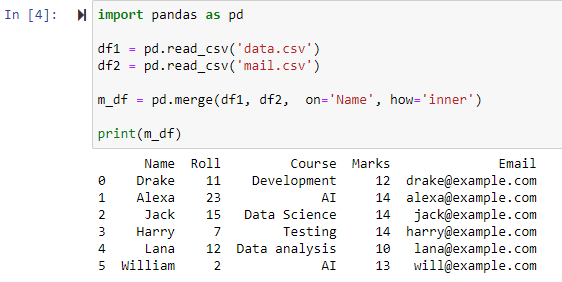
جیسا کہ دیکھا جا سکتا ہے کہ فنکشن نے دونوں CSV فائلوں کو ضم کر دیا ہے اور کالم 'نام' کی مشترکہ صفات کی بنیاد پر قطاریں واپس کر دی ہیں۔
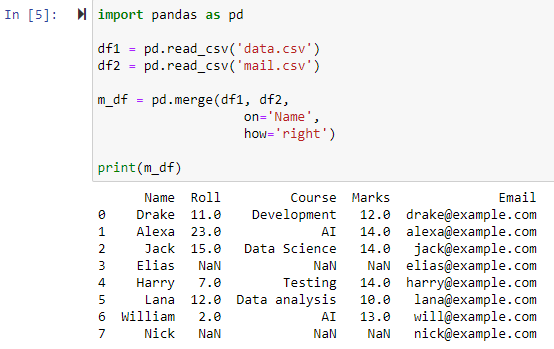
دائیں بیرونی شمولیت کا استعمال کرتے ہوئے ضم کریں۔
جب پیرامیٹر how='right' متعین کیا جاتا ہے، تو دونوں ڈیٹا فریم اس کالم کی بنیاد پر اکٹھے کیے جائیں گے جو ہم نے پیرامیٹر 'آن' کے لیے مخصوص کیا ہے۔ اور ایک نیا ڈیٹا فریم جس میں دائیں ڈیٹا فریم کی تمام قطاریں ہوں، بشمول کوئی بھی قطار جس کے لیے بائیں ڈیٹا فریم میں کوئی قدر نہیں ہے، واپس کر دی جائے گی، بائیں ڈیٹا فریم کے کالم کی قدر کو NAN پر سیٹ کرنے کے ساتھ۔
بائیں بیرونی شمولیت کا استعمال کرتے ہوئے ضم کریں۔
جب پیرامیٹر کو 'بائیں' کے بطور متعین کیا جاتا ہے تو، 'آن' پیرامیٹر کا استعمال کرتے ہوئے مخصوص کالم کی بنیاد پر دونوں ڈیٹا فریموں کو جوڑ دیا جائے گا، ایک نیا ڈیٹا فریم لوٹایا جائے گا جس میں بائیں ڈیٹا فریم کی تمام قطاریں ہوں گی اور ساتھ ہی ایسی کوئی قطار جس میں NAN ہو یا صحیح ڈیٹا فریم میں null ویلیوز اور صحیح ڈیٹا فریم کالم ویلیو کو NAN پر سیٹ کرتا ہے۔
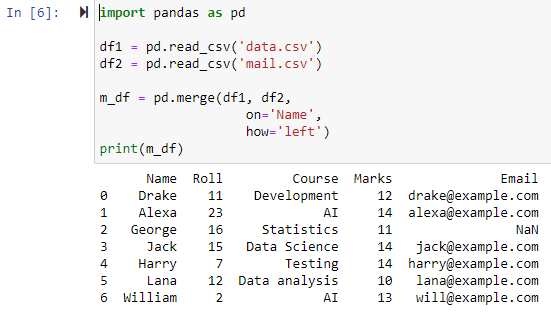
مکمل بیرونی شمولیت کا استعمال کرتے ہوئے ضم کریں۔
جب how='outer' کی وضاحت کی جاتی ہے، تو 'آن' پیرامیٹر کے لیے مخصوص کردہ کالم کی بنیاد پر دونوں ڈیٹا فریموں کو جوڑ دیا جائے گا، ایک نیا ڈیٹا فریم لوٹائے گا جس میں df1 اور df2 ڈیٹا فریم دونوں کی قطاریں ہوں گی اور NAN کو کسی بھی قطار کے لیے قدر کے طور پر سیٹ کریں گے۔ جس کے لیے ڈیٹا فریم میں سے کسی ایک میں ڈیٹا غائب ہے۔
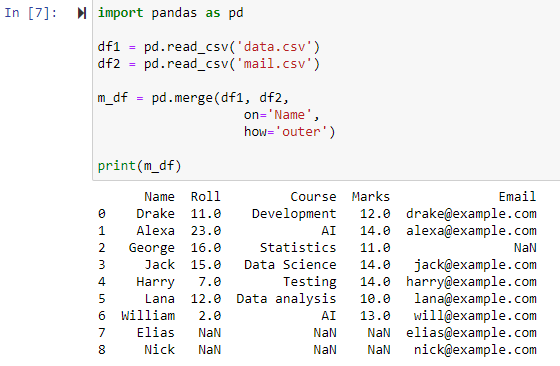
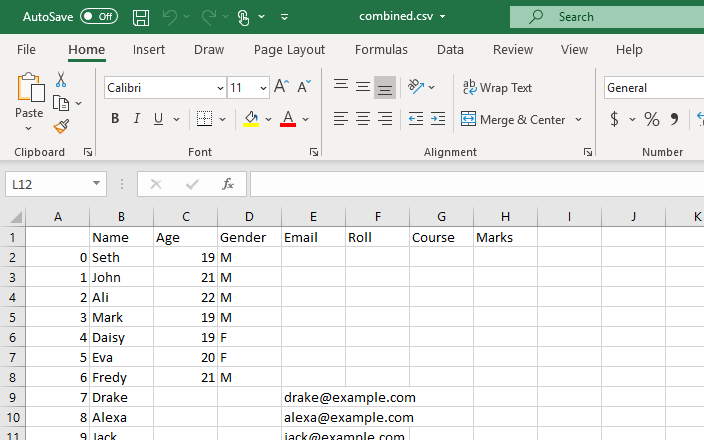
مثال نمبر 2: ورکنگ ڈائرکٹری میں تمام CSV فائلوں کو یکجا کرنا
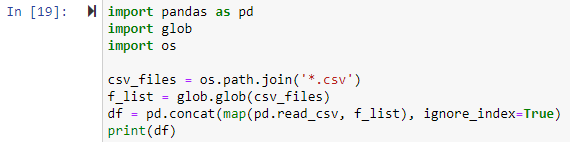
اس طریقے میں، ہم تمام .csv فائلوں کو ایک پانڈاس ڈیٹا فریم میں جوڑنے کے لیے گلوب ماڈیول کا استعمال کریں گے۔ تمام لائبریریوں کو پہلے درآمد کرنا پڑا۔ اگلا، ہم ہر CSV فائل کے لیے ایک راستہ طے کریں گے جسے ہم جوڑنا چاہتے ہیں۔ فائل پاتھ نیچے دی گئی مثال میں os.path.join() فنکشن کے لیے پہلی دلیل ہے، اور دوسری دلیل یا تو پاتھ کے اجزاء یا .csv فائلوں کو جوائن کرنا ہے۔ یہاں، اظہار '*.csv' کام کرنے والی ڈائرکٹری میں ہر فائل کو تلاش کرے گا اور واپس کرے گا جو .csv فائل ایکسٹینشن کے ساتھ ختم ہوتی ہے۔ glob.glob(files joined) فنکشن ضم شدہ فائلوں کے ناموں کی فہرست کو بطور ان پٹ قبول کرتا ہے اور تمام ضم شدہ/مشترکہ فائلوں کی فہرست کو آؤٹ پٹ کرتا ہے۔
یہ اسکرپٹ ہماری ورکنگ ڈائرکٹری میں موجود تمام CSV فائلوں کے مشترکہ ڈیٹا کے ساتھ ایک ڈیٹا فریم واپس کرے گا۔
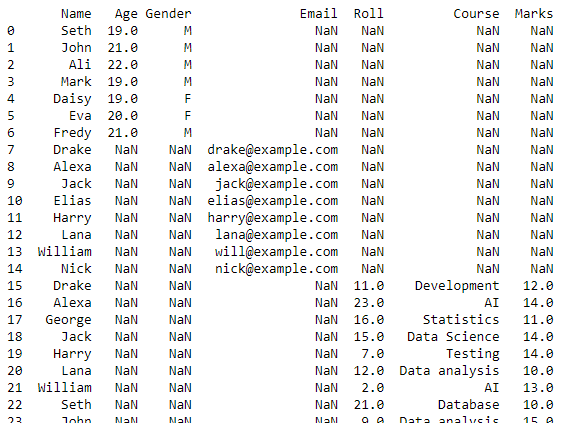
یہ ڈیٹا فریم ایک CSV فائل میں تبدیل ہو جائے گا، اور to_csv() فنکشن اس تبدیلی کے لیے استعمال کیا جائے گا۔ یہ نئی CSV فائل مشترکہ CSV فائلیں ہوں گی جو موجودہ ورکنگ ڈائرکٹری میں محفوظ کردہ تمام CSV فائلوں سے بنائی گئی ہیں۔
نتیجہ
اس پوسٹ میں، ہم نے بحث کی کہ ہمیں CSV فائلوں کو یکجا کرنے کی ضرورت کیوں ہے۔ ہم نے بحث کی کہ دو یا دو سے زیادہ CSV فائلوں کو Python میں کیسے ملایا جا سکتا ہے۔ ہم نے اس ٹیوٹوریل کو دو حصوں میں تقسیم کیا ہے۔ پہلے حصے میں، ہم نے وضاحت کی کہ ایک ہی ڈھانچے یا کالم کے ناموں کی CSV فائلوں کو یکجا کرنے کے لیے append() اور concat() فنکشنز کو کیسے استعمال کیا جائے۔ دوسرے حصے میں، ہم نے مختلف کالموں اور ڈھانچے کی CSV فائلوں کو یکجا کرنے کے لیے merge() طریقہ، os.path.join() اور گلوب طریقہ استعمال کیا۔