Amazon Redshift AWS کی طرف سے پیش کردہ ایک کلاؤڈ حل ہے جو ڈیٹا گودام کا مقصد پورا کرتا ہے۔ ڈیٹا گودام کلاؤڈ میں ایک بڑی جگہ ہے جو بہت زیادہ ڈیٹا کو ذخیرہ کرتا ہے۔ ڈیٹا گودام اور ڈیٹا بیس کے درمیان فرق یہ ہے کہ سابقہ نہ صرف موجودہ ڈیٹا بلکہ ڈیٹا کی مکمل تاریخ کو بھی محفوظ کرتا ہے۔
یہ مضمون AWS کے ذریعے Amazon Redshift اور ڈیٹا کی ان اقسام کے بارے میں سیکھے گا جن کی یہ سروس سپورٹ کرتی ہے۔
ایمیزون ریڈ شفٹ کیا ہے؟
یہ ڈیٹا ویئر ہاؤسنگ کا کلاؤڈ حل ہے جس پر مبنی ہے۔ 'پوسٹگری ایس کیو ایل' . یہ ایک ٹیکنالوجی کا استعمال کرتا ہے جسے کہا جاتا ہے 'بڑے پیمانے پر متوازی پروسیسنگ (MPP)' بجلی کی رفتار سے ڈیٹا کے پیٹا بائٹس پر کارروائی کرنے کے لیے۔ یہ تاریخی اعداد و شمار اور سلسلہ بندی کے حل کی بنیاد پر حقیقی وقت کی پیشن گوئی کے لیے ایک آسان حل فراہم کرتا ہے۔
مندرجہ ذیل اعداد و شمار Amazon Redshift کے ورکنگ میکانزم کو ظاہر کرتا ہے:
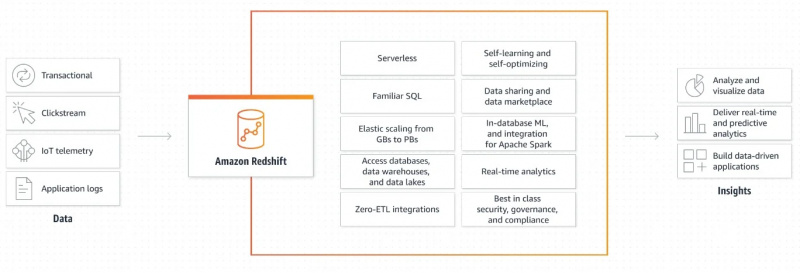
Amazon Redshift کیسے کام کرتا ہے اس کی گرافیکل وضاحت بہت آسان اور واضح ہے۔ یہ ہمیں اس بارے میں معلومات فراہم کرتا ہے کہ کس طرح ڈیٹا کو بازیافت کیا جاتا ہے اور آؤٹ پٹ پیدا کرنے اور ڈیٹا سے چلنے والی ایپلی کیشنز بنانے کے لیے مزید کارروائی کی جاتی ہے۔
ایمیزون ریڈ شفٹ کے ڈیٹا گودام کے فن تعمیر کو نیچے دی گئی تصویر میں بھی دیکھا جا سکتا ہے:
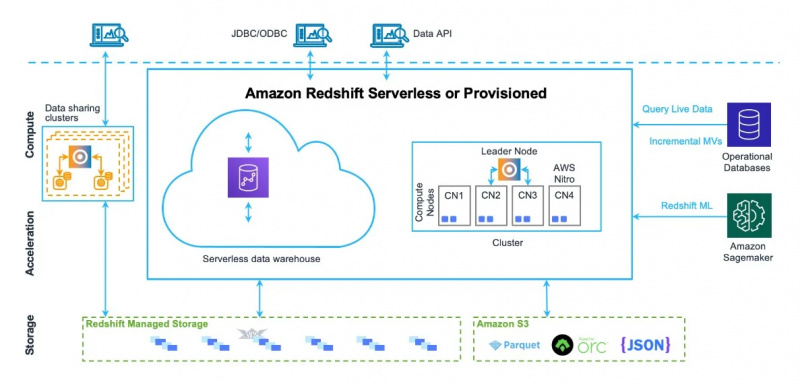
اب، ہم اس سروس کے استعمال اور خصوصیات کی طرف جائیں گے۔
خصوصیات
جیسا کہ پہلے ہی ذکر کیا گیا ہے، Amazon Redshift PostgreSQL پر مبنی ہے اور ایک ایسی ٹیکنالوجی کا استعمال کرتی ہے جسے Massively Parallel Processing کہا جاتا ہے جو اسے بغیر وقت کے ڈیٹا کے پیٹا بائٹس پر کارروائی کرنے کے قابل بناتا ہے۔ لہذا، Redshift خصوصیات اور استعمال کی ایک اچھی تعداد پیش کرتا ہے. ان میں سے کچھ خصوصیات ذیل میں ہیں:
- ڈیٹا سیکیورٹی اور انکرپشن۔
- کاروباری تجزیات۔
- ڈیٹا سے چلنے والی ایپلیکیشن سپورٹ۔
- پیش گوئی کرنے والا تجزیہ۔
- خودکار ٹاسک کی تکرار۔
- سمورتی ڈیٹا اسکیلنگ۔
- ڈیٹا سٹوریج.
اس سروس کی کچھ اضافی خصوصیات ذیل میں دی گئی تصویر میں دیکھی جا سکتی ہیں:
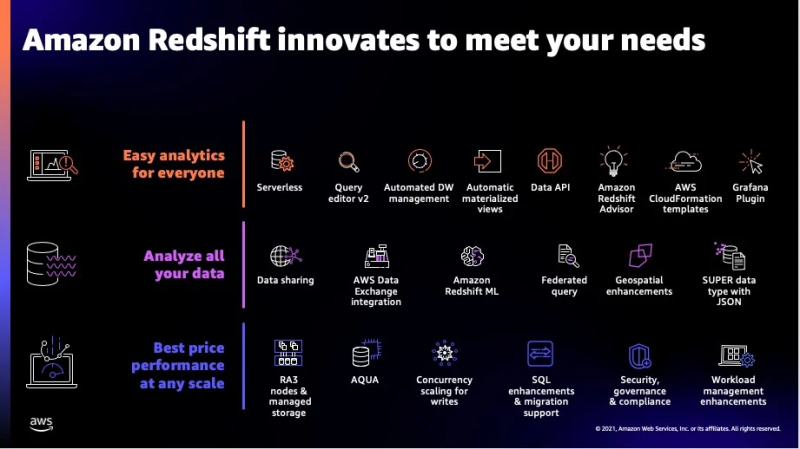
یہ وہ زیادہ تر خصوصیات تھیں جو Redshift پیش کرتی ہیں اور اب ہم اس سروس کے ذریعے تعاون یافتہ ڈیٹا کی اقسام پر جائیں گے۔
ڈیٹا کی اقسام
Amazon Redshift ایک ڈیٹا ویئر ہاؤسنگ حل ہے جس میں بہت ساری خصوصیات ہیں۔ یہ ساختی اور غیر ساختہ ڈیٹا دونوں قسموں کی حمایت کرتا ہے۔ جیسا کہ یہ PostgreSQL پر مبنی ہے، اس لیے ڈیٹا کو سادہ SQL سوالات کے ذریعے ہیرا پھیری کیا جا سکتا ہے۔
اب، ایک اور سوال پیدا ہوتا ہے، یعنی یہ ڈیٹا فارمیٹس ایک دوسرے سے کیسے مختلف ہیں؟ آئیے ان دو ڈیٹا فارمیٹس پر بات کرتے ہیں۔
سٹرکچرڈ ڈیٹا
ایک انتہائی فارمیٹ شدہ ڈیٹا کی قسم جس کا آسانی سے مشین لرننگ الگورتھم کے ذریعے ترجمہ کیا جاتا ہے اسے سٹرکچرڈ ڈیٹا کہا جاتا ہے۔ ایس کیو ایل ڈیٹا بیس سٹرکچرڈ ڈیٹا کے ساتھ کام کرتا ہے۔ سٹرکچرڈ ڈیٹا ٹیبلر شکل میں ہوتا ہے جیسے کہ متعلقہ ڈیٹا بیس کے ذریعے استعمال ہونے والا ڈیٹا
وسیع پیمانے پر استعمال ہونے والے SQL ڈیٹا بیس مینجمنٹ سسٹمز میں سے ایک MYSQL ہے۔ اس کا فن تعمیر ذیل میں دی گئی شکل میں دیکھا جا سکتا ہے:
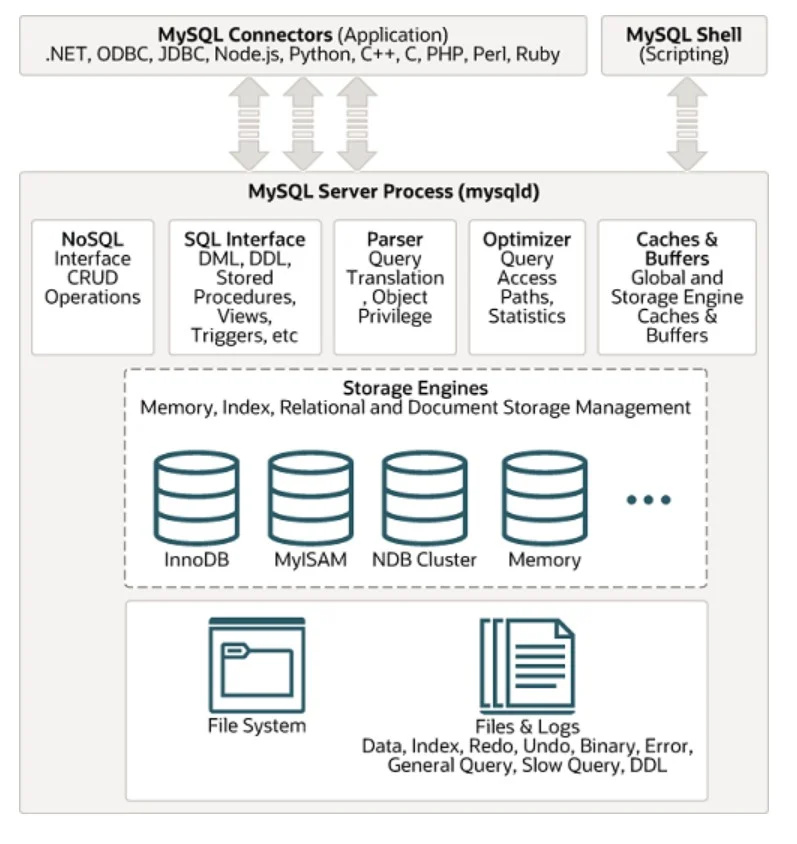
غیر ساختہ ڈیٹا
غیر ساختہ ڈیٹا پیٹرن کم اور فارمیٹ کم ڈیٹا ہے جیسا کہ ڈیٹا غیر متعلقہ ڈیٹا بیس میں استعمال ہوتا ہے۔ MongoDB ایک مشہور غیر متعلقہ ڈیٹا بیس ہے۔ ایس کیو ایل کے سوالات غیر متعلقہ ڈیٹا بیس پر کام نہیں کرتے، اس لیے ان ڈیٹا بیس کو NoSQL ڈیٹا بیس بھی کہا جاتا ہے۔
جیسا کہ پہلے ہی ذکر کیا گیا ہے، MongoDB ایک غیر ساختہ ڈیٹا بیس مینجمنٹ سسٹم ہے اور اس کا فن تعمیر ذیل میں دی گئی شکل میں دیکھا جا سکتا ہے:
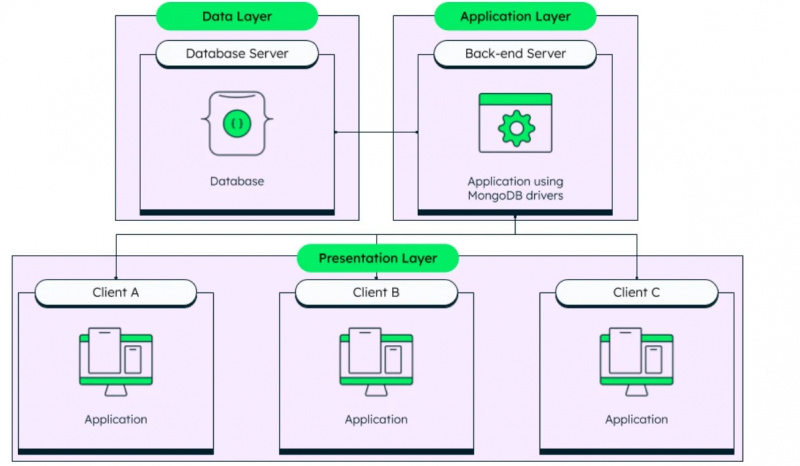
ہم ڈیٹا بیس میں استعمال ہونے والی دو بنیادی ڈیٹا کی اقسام سے گزر چکے ہیں اور اب ہم اصل ڈیٹا کی اقسام کی طرف جائیں گے جو Amazon Redshift کے ذریعے تعاون یافتہ ہیں۔ ڈیٹا کی یہ اقسام ہیں:
- عددی ڈیٹا
- کریکٹر ڈیٹا
- ڈیٹ ٹائم ڈیٹا
- بولین ڈیٹا
- HLLSKETCH ڈیٹا
- سپر ڈیٹا
- ریپلیسمنٹ ڈیٹا
آئیے ان ڈیٹا کی اقسام پر بات کریں:
عددی ڈیٹا
یہ ڈیٹا کی قسم خود وضاحتی ہے۔ یہ اعداد و شمار کو سپورٹ کرتا ہے جو انٹیجرز، ڈیسیملز، فلوٹنگ پوائنٹ اور دیگر عددی ڈیٹا کی اقسام کی شکل میں ہے۔
انٹیجر ڈیٹا کی قسم کی خصوصیات کو نیچے دی گئی تصویر میں دیکھا جا سکتا ہے:
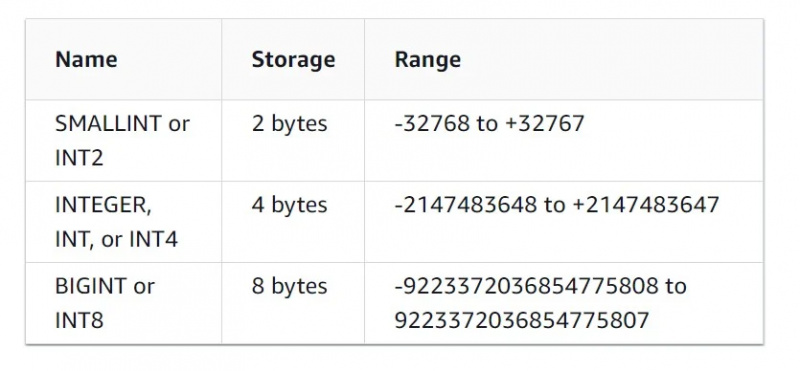
اعشاریہ ڈیٹا کی قسم صارف کی طرف سے درستگی کی بنیاد پر ڈیٹا کو ذخیرہ کرتی ہے۔ اس کی خصوصیات درج ذیل ہیں:

کریکٹر ڈیٹا
CHAR اور VARCHAR ڈیٹا کی قسمیں کریکٹر پر مبنی ڈیٹا کی اقسام کے زمرے میں آتی ہیں۔ NCHAR اور NVARCHAR بھی کریکٹر ٹائپ ڈیٹا کی قسمیں ہیں۔ CHAR اور VARCHAR کے برعکس، یہ دونوں ڈیٹا کی قسمیں مقررہ لمبائی، یونیکوڈ حروف کو محفوظ کرتی ہیں۔ آئیے ان ڈیٹا کی اقسام کی خصوصیات کو دیکھتے ہیں، جیسے:
- CHAR، CHARACTER، NCHAR کی رینج 4KB ہے۔
- VARCHAR، NVARCHAR کی رینج 64KB ہے۔
- BPCHAR کی رینج 256 بائٹس ہے۔
- TEXT کی رینج 260 بائٹس ہے۔
ڈیٹ ٹائم ڈیٹا
ڈیٹ ٹائم ڈیٹا کی اقسام DATE، TIME، TIMETZ، TIMESTAMP، TIMESTAMPTZ ہیں۔ ان ڈیٹا کی اقسام کی فنکشنل صلاحیتیں درج ذیل ہیں:
- DATE صرف کیلنڈر کی تاریخوں کو اسٹور کرتی ہے۔
- TIME کسی بھی ٹائم زون کے حوالے کے بغیر وقت کو اسٹور کرتا ہے۔ یہ UTC ہے، بطور ڈیفالٹ۔
- TIMETZ ٹائم زون کے حوالے سے وقت کو اسٹور کرتا ہے۔ یہ یوزر ٹیبلز اور سسٹم ٹیبلز دونوں میں بطور ڈیفالٹ UTC ہے۔
- TIMESTAMP میں نہ صرف وقت بلکہ تاریخیں بھی شامل ہوتی ہیں۔ یہ یوزر ٹیبلز اور سسٹم ٹیبلز دونوں میں بطور ڈیفالٹ UTC ہے۔
- TIMESTAMPTZ میں نہ صرف وقت بلکہ تاریخیں بھی شامل ہوتی ہیں۔ یہ صرف یوزر ٹیبلز میں UTC ہے، بطور ڈیفالٹ۔
بولین ڈیٹا
بولین ڈیٹا کی قسم ایک بائنری ڈیٹا کی قسم ہے، جس کا مطلب ہے کہ صرف دو قدریں ہیں۔ بولین ڈیٹا کی قسم کے لیے خصوصیات کا جدول تصویر میں ذیل میں دیا گیا ہے۔
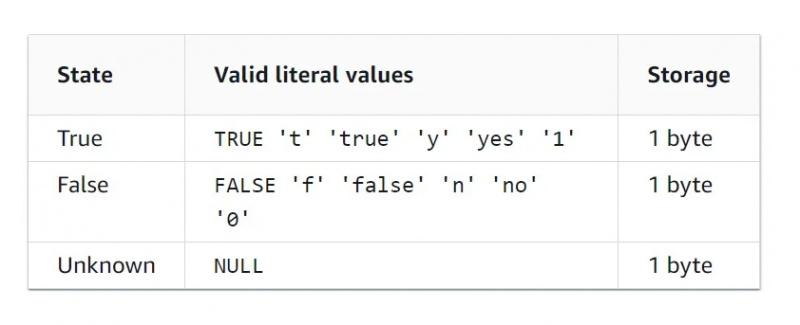
HLLSKETCH ڈیٹا
اس ڈیٹا کی قسم کو خاکوں کو ذخیرہ کرنے کے لیے استعمال کیا جاتا ہے۔ ریڈ شفٹ خاکوں کی نمائندگی یا تو ویرل یا گھنے شکل میں کر سکتا ہے۔ خاکے ویرل کے طور پر شروع ہوتے ہیں اور آہستہ آہستہ گھنے ہو جاتے ہیں جب ایک گھنے فارمیٹ لنک پر عمل کرتے ہوئے زیادہ کارکردگی فراہم کرتا ہے۔
سپر ڈیٹا
ڈیٹا کی یہ قسم غیر ساختہ ڈیٹا سے متعلق ہے جو صفوں، نیسٹڈ ڈھانچے، یا JSON کی شکل میں ہو سکتا ہے۔ ڈیٹا کا کوئی ماڈل یا فارمیٹ نہیں ہے۔ صارف لنک پر جا کر مزید معلومات کو دریافت کر سکتے ہیں۔
ریپلیسمنٹ ڈیٹا
یہ ڈیٹا ٹائپ کریکٹرز کو بھی اسٹور کرتا ہے۔ تاہم، لمبائی محدود ہے. Amazon Redshift VARBYTE ڈیٹا کو کسی بھی عددی قسم یا کردار کی قسم کے ڈیٹا میں ڈالنے کی اجازت دیتا ہے۔ اس ڈیٹا ٹائپ کے بارے میں مزید معلومات حاصل کرنے کے لیے، نیچے دیے گئے لنک کو فالو کریں۔
ایمیزون ریڈ شفٹ اور اس کی حمایت کرنے والی ڈیٹا کی اقسام کے لیے یہ سب کچھ ہے۔
نتیجہ
Amazon Redshift ایک AWS سروس ہے جو اپنی بنیادی شکل میں ڈیٹا گودام کا مقصد پورا کرتی ہے لیکن تجزیات اور پیشین گوئی کے لیے ایک بہت ہی طاقتور اور نمایاں حل ہے۔ اس مضمون میں Redshift اور ڈیٹا کی اقسام پر تبادلہ خیال کیا گیا ہے جو اس کی حمایت کرتا ہے۔ ان ڈیٹا کی اقسام کو ان کی خصوصیات کے ساتھ مختصراً بیان کیا گیا تھا۔