'پانڈا' میں، ہم 'پانڈا' طریقہ کی مدد سے ٹیکسٹ فائل کو آسانی سے پڑھ سکتے ہیں۔ 'پانڈا' ہمیں ٹیکسٹ فائل کو پڑھنے کا موقع فراہم کرتا ہے۔ 'پانڈا' ٹیکسٹ فائل کو پڑھنے کے لیے مختلف بلٹ ان طریقے فراہم کرتا ہے۔ ہم یہاں تمام پیرامیٹرز کے ساتھ اس ٹیوٹوریل میں تمام طریقوں پر تبادلہ خیال کریں گے اور ان کی تفصیل سے وضاحت کریں گے۔ اس کے علاوہ، ہم یہاں اپنے کوڈز میں 'پانڈا' کے طریقے استعمال کرکے 'پانڈا' میں ٹیکسٹ فائل پڑھیں گے۔'
'پانڈا' میں ٹیکسٹ فائل کو پڑھنے کے طریقے
'پانڈا' میں، ہمارے پاس تین طریقے ہیں جو ٹیکسٹ فائل کو پڑھنے میں ہماری مدد کرتے ہیں۔ ہم نے یہاں کچھ مثالیں بھی کی ہیں جن میں ہم ٹیکسٹ فائل کو پڑھتے ہیں۔ وہ طریقے جو 'پانڈا' فراہم کرتے ہیں ذیل میں زیر بحث آئے ہیں۔
-
- pd.read_csv() طریقہ استعمال کرکے۔
- pd.read_table() طریقہ استعمال کرکے۔
- pd.read_fwf() طریقہ استعمال کرکے۔
اب، ہم ان تمام طریقوں کے نحو کی وضاحت کر رہے ہیں اور اس ٹیوٹوریل میں تمام طریقوں کے پیرامیٹرز پر تفصیل سے بحث کر رہے ہیں۔
read_csv() کا نحو
pd.read_csv ( 'filename.txt'، ستمبر =''، ہیڈر =کوئی نہیں، نام = [ 'Col_name1'، 'col_name2، 'col_name2'، ……….. ] )
اس طریقے میں، ہم سب سے پہلے اس ٹیکسٹ فائل کا نام شامل کرتے ہیں جس کا ڈیٹا ہم پڑھنا چاہتے ہیں، اور یہ اس طریقہ کا پہلا پیرامیٹر ہے۔ اس کے بعد، ہم 'sep' رکھتے ہیں، جو اس طریقہ کار میں ایک الگ کرنے والا ہے، اور ہم یہاں اسپیس کو کریکٹر کے طور پر رکھتے ہیں تو یہ اسپیس کو الگ کرنے والا سمجھے گا۔ اس کے بعد، ہمارے پاس ہیڈر پیرامیٹر ہے، اور اس پیرامیٹر کی 'کوئی نہیں' ویلیو استعمال ہوتی ہے، تو یہ ڈیفالٹ ہیڈر بنائے گا، اور اگر ہم اس پیرامیٹر کو شامل نہیں کرتے ہیں، تو یہ ٹیکسٹ فائل کی پہلی لائن پر غور کرے گا۔ ہیڈر کے طور پر. 'نام' پیرامیٹر میں، ہم کالم کے نام شامل کر سکتے ہیں جنہیں ہمیں ہیڈر کے طور پر شامل کرنا ہے۔
read_table() کا نحو
pd.read_table ( 'filename.txt' ، حد بندی = '' )
اس طریقہ میں، ہم ٹیکسٹ فائل کے فائل کا نام پہلے پیرامیٹر کے طور پر رکھتے ہیں۔ ڈیلیمیٹر میں، جب ہم '' کو رکھیں گے، تو یہ سپیس کریکٹر کو الگ کرنے والے کے طور پر لے گا۔
read_fwf() کا نحو
pd.read_fwf ( 'filename.txt' )
یہ طریقہ صرف ایک پیرامیٹر لیتا ہے، جو کہ ٹیکسٹ فائل کا نام ہے۔
اب، ہم 'پانڈا' کوڈز میں ٹیکسٹ فائلوں کو پڑھنے اور ٹرمینل پر ٹیکسٹ فائل کا ڈیٹا دکھانے کے لیے یہ طریقے استعمال کریں گے۔
مثال نمبر 01
'Spyder' ایپ یہاں ہے جس میں ہم نے یہ تمام کوڈز کیے ہیں جو اس ٹیوٹوریل میں پیش کیے گئے ہیں۔ ٹیکسٹ فائل جس کا ڈیٹا ہم پڑھنا چاہتے ہیں ذیل میں دکھایا گیا ہے۔ اس ٹیکسٹ فائل کو 'پانڈا' میں پڑھنے کے لیے ہم 'read_csv()' طریقہ استعمال کریں گے۔
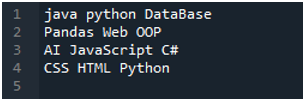
ہم سب سے پہلے 'پانڈا' لائبریری کو درآمد کرتے ہیں کیونکہ ہم 'read_csv()' طریقہ استعمال کرنا چاہتے ہیں، اور یہ 'پانڈا' کا طریقہ ہے۔ ہم صرف اس طریقہ تک رسائی حاصل کرتے ہیں جب ہم نے 'پانڈا' کی لائبریری درآمد کی ہے۔ یہاں، ہم 'پانڈا بطور pd' کا ذکر کرتے ہیں، اس لیے یہ 'pd' اسے استعمال کرنے کے طریقے کے نام کے ساتھ رکھا گیا ہے۔ اس کے بعد، ہم یہاں ایک متغیر 'df' بناتے ہیں، جو پڑھنے کے بعد ٹیکسٹ فائل کے ڈیٹا کو محفوظ کرنے کے لیے استعمال ہوتا ہے۔ ہم یہاں 'pd.read_csv()' طریقہ رکھتے ہیں، جو ٹیکسٹ فائل کو پڑھنے اور ٹیکسٹ فائل کے ڈیٹا کو ڈیٹا فریم میں تبدیل کرنے اور اسے 'df' متغیر میں اسٹور کرنے میں مدد کرتا ہے۔
ہم نے فائل کا نام پاس کیا ہے، جو کہ 'myData.txt' ہے، اور پھر ہم 'sep' استعمال کرتے ہیں اور اس 'sep' کو خالی حرف تفویض کرتے ہیں۔ لہذا، یہ خالی کریکٹر ٹیکسٹ فائل میں الگ کرنے والے کے طور پر کام کرتا ہے۔ پھر، ہم نے نیچے 'print()' کا استعمال کیا، جو ٹیکسٹ فائل کے ڈیٹا کو پرنٹ کرنے کے لیے استعمال ہوتا ہے۔ یہ ٹیکسٹ فائل کا ڈیٹا ڈیٹا فریم فارم میں ظاہر کرے گا۔
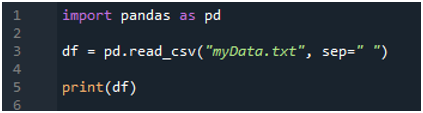
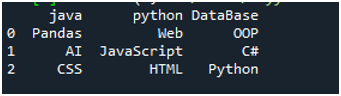
اس کوڈ کے نفاذ کے لیے، ہمیں 'Shift+Enter' دبانا ہوگا اور آؤٹ پٹ 'Spyder's' ٹرمینل پر پیش کیا جائے گا۔ مندرجہ بالا کوڈ کا نتیجہ دیئے گئے اسکرین شاٹ میں ظاہر ہوتا ہے، اور آپ دیکھ سکتے ہیں کہ ٹیکسٹ فائل کا ڈیٹا ڈیٹا فریم کے طور پر ظاہر ہوتا ہے، اور ہماری ٹیکسٹ فائل کی پہلی لائن اس ڈیٹا فریم کے کالم کے ناموں کے طور پر یہاں پیش کی گئی ہے۔ یہ ڈیٹا کو بھی الگ کرتا ہے جہاں اسپیس کریکٹر ٹیکسٹ فائل میں موجود ہے۔
مثال نمبر 02
ٹیکسٹ فائل جسے ہم اس مثال میں پڑھیں گے وہ یہاں دکھائی گئی ہے، اور ہم دوبارہ 'read_csv()' طریقہ استعمال کریں گے لیکن مختلف پیرامیٹرز کے ساتھ۔
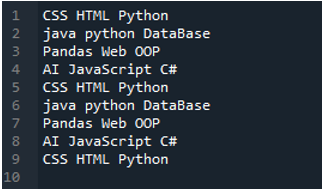
'پانڈا' طریقہ 'pd.read_csv()' استعمال کیا جاتا ہے، اور ہم یہاں تین پیرامیٹرز پاس کرتے ہیں۔ سب سے پہلے، ہم فائل کا نام رکھتے ہیں، جو کہ 'Record.txt' ہے۔ دوسرا پیرامیٹر 'sep' پیرامیٹر ہے اور اسے خالی کریکٹر تفویض کرتا ہے، اور پھر ہمارے پاس تیسرا پیرامیٹر ہے جس میں ہم 'ہیڈر' سیٹ کرتے ہیں اور اسے 'کوئی نہیں' میں ایڈجسٹ کرتے ہیں، تو یہ ڈیٹا فریم کا ڈیفالٹ ہیڈر بنائے گا۔ جب ہم اس کوڈ پر عمل کرتے ہیں۔ ہم نے یہ سب 'My_Record' ویری ایبل میں محفوظ کیا ہے اور پرنٹنگ کے لیے 'print()' فنکشن میں 'My_Record' کو بھی شامل کیا ہے۔

تمام ڈیٹا ڈیٹا فریم میں محفوظ ہوتا ہے، اور یہ ڈیٹا کو الگ کرتا ہے جہاں اسپیس کریکٹر ٹیکسٹ فائل ڈیٹا میں موجود ہوتا ہے۔ نیز، اس نے یہاں ڈیٹا فریم کا ڈیفالٹ ہیڈر بنایا کیونکہ ہم نے 'ہیڈر' پیرامیٹر کو 'کوئی نہیں' میں ایڈجسٹ کیا۔
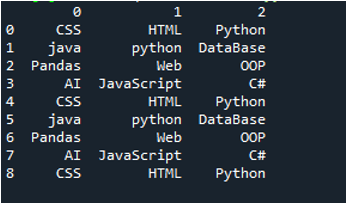
مثال نمبر 03
اس مثال کی ٹیکسٹ فائل ظاہر ہوتی ہے، اور ہم ایک بار پھر ترمیم شدہ پیرامیٹرز کے ساتھ 'read_csv()' طریقہ استعمال کریں گے۔
اس کوڈ میں، چار پیرامیٹرز کو یہاں 'پانڈا' طریقہ 'pd.read_csv()' میں منتقل کیا گیا ہے۔ ٹیکسٹ فائل کا نام پہلا پیرامیٹر ہے۔ دوسرے پیرامیٹر میں 'sep' پیرامیٹر کو خالی کریکٹر دیا گیا ہے۔ تیسری دلیل میں 'ہیڈر' پیرامیٹر کو 'کوئی نہیں' پر سیٹ کیا گیا ہے، اور چوتھے پیرامیٹر کے طور پر، ہم نے 'نام' سیٹ کیا ہے جو ٹیکسٹ فائل کو پڑھنے کے بعد ڈیٹا فریم کے کالم کے ناموں کے طور پر ظاہر ہوں گے، اور یہ کالم کے نام ہیں۔ 'COL_1، COL_2، COL_3، COL_4، اور COL_5'۔ یہ تمام معلومات 'My_Record' متغیر میں محفوظ کی گئی ہیں، اور 'My_Record' کو 'print()' طریقہ میں بھی شامل کیا گیا ہے تاکہ یہ ٹرمینل پر پرنٹ ہوجائے۔

ٹیکسٹ فائل کی تمام معلومات کو یہاں ڈیٹا فریم کے طور پر پیش کیا گیا ہے، اور یہ اس ڈیٹا کو بھی الگ کرتا ہے جہاں ٹیکسٹ فائل میں خالی جگہیں شامل کی گئی ہیں۔ اس کے مطابق کالم کے نام بھی شامل کیے جاتے ہیں، جو ہم نے اوپر کوڈ میں شامل کیے ہیں۔
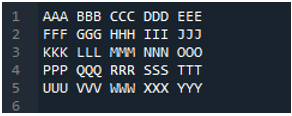
مثال نمبر 04
یہ وہ ٹیکسٹ فائل ہے جسے ہم اس مثال میں ایک اور طریقہ، 'pd.read_table()' طریقہ استعمال کرکے پڑھیں گے۔
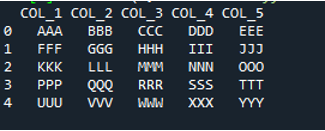
ٹیکسٹ فائل کو پڑھنے کے لیے یہاں 'pd.read_table()' طریقہ شامل کیا گیا ہے، اور ہم 'ABC.txt' شامل کرتے ہیں، جو کہ ٹیکسٹ فائل کا نام ہے۔ یہ طریقہ ٹیکسٹ فائل کو پڑھنے میں مدد کرتا ہے، اور ساتھ ہی، ہم نے 'ڈیلیمیٹر' پیرامیٹر کو اسپیس کریکٹر میں ایڈجسٹ کیا ہے، اس لیے یہ اس سیپریٹر کی طرح بھی کام کرے گا جس کی ہم نے اوپر وضاحت کی ہے۔ پھر ٹیکسٹ کا تمام فائل ڈیٹا 'My_Data' متغیر میں محفوظ کیا جاتا ہے اور یہاں پرنٹ بھی ہوتا ہے۔

ہماری ٹیکسٹ فائل کی ابتدائی لائن یہاں ڈیٹا فریم کے کالم کے نام کے طور پر دکھائی گئی ہے، اور ٹیکسٹ فائل کا ڈیٹا ڈیٹا فریم کے طور پر پرنٹ کیا گیا ہے۔ مزید برآں، یہ ٹیکسٹ فائل کے ڈیٹا کو الگ کرتا ہے جہاں اسپیس کریکٹر اس میں موجود ہے۔
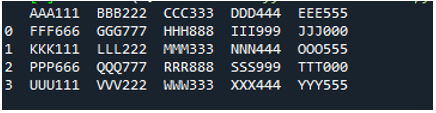
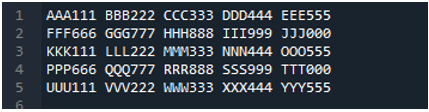
مثال نمبر 05
اب، ٹیکسٹ فائل میں ڈیٹا ہے، جو نیچے دکھایا گیا ہے۔ ہم اس بار 'read_fwf()' کا اطلاق کریں گے اور دکھائیں گے کہ یہ ٹیکسٹ فائل کو پڑھنے کے بعد ڈیٹا کو کیسے رینڈر کرتا ہے۔
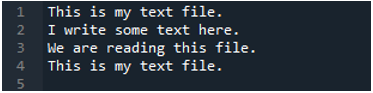
جیسا کہ ہم جانتے ہیں کہ یہ 'read_fwf()' طریقہ صرف ایک پیرامیٹر لیتا ہے، جو کہ فائل کا نام ہے جسے ہم پڑھنا چاہتے ہیں۔ ہم یہاں 'textfile.txt' کو شامل کرتے ہیں، جو ہماری ٹیکسٹ فائل کا نام ہے اور اس پانڈاس طریقہ کو 'File_Data' متغیر کو تفویض کرتے ہیں، جو اس ٹیکسٹ فائل کا ڈیٹا محفوظ کرے گا۔ پھر ہم نے 'print(File_Data)' ڈالا تو یہ اس ڈیٹا کو بھی پرنٹ کرتا ہے۔

یہاں، ٹیکسٹ فائل کا تمام ڈیٹا دکھایا گیا ہے۔ اس نے ڈیٹا کو الگ نہیں کیا جہاں اسپیس کریکٹرز موجود ہیں کیونکہ اس فنکشن میں 'Sep' یا 'delimiter' جیسا کوئی پیرامیٹر نہیں ہے۔
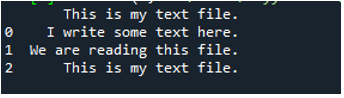
نتیجہ
یہ ٹیوٹوریل بتاتا ہے کہ 'پانڈا' میں ٹیکسٹ فائل کو کیسے پڑھا جائے اور 'پانڈا' میں ٹیکسٹ فائل پڑھنے کے لیے کون سے طریقے استعمال کیے جاتے ہیں۔ ہم نے ان تمام طریقوں پر تبادلہ خیال کیا ہے جو 'پانڈا' میں ٹیکسٹ فائل کو پڑھنے میں ہماری مدد کرتے ہیں۔ ہم نے اس ٹیوٹوریل میں 'پانڈا' میں اپنی ٹیکسٹ فائلوں کو پڑھنے کے لیے 'پانڈا' کے تین مختلف طریقے دریافت کیے ہیں۔ ہم نے یہاں تمام طریقوں کے نحو کے ساتھ ساتھ تمام طریقوں کے پیرامیٹرز کو بھی تفصیل سے بیان کیا ہے اور اس ٹیوٹوریل میں تمام ممکنہ پیرامیٹرز کے ساتھ مختلف طریقے استعمال کرکے بہت سی ٹیکسٹ فائلوں کو پڑھا ہے۔