پانڈوں نے NaN قدریں بھریں۔
اگر آپ کے ڈیٹا فریم میں کسی کالم میں NaN یا None کی قدریں ہیں، تو آپ 'fillna()' یا 'replace()' فنکشنز کو صفر (0) سے بھرنے کے لیے استعمال کر سکتے ہیں۔
بھریں()
NA/NaN کی قدریں 'filna()' فنکشن کا استعمال کرتے ہوئے فراہم کردہ نقطہ نظر سے بھری ہوئی ہیں۔ اسے درج ذیل نحو پر غور کرکے استعمال کیا جاسکتا ہے۔
اگر آپ ایک کالم کے لیے NaN اقدار کو پُر کرنا چاہتے ہیں تو نحو درج ذیل ہے:

جب آپ کو مکمل ڈیٹا فریم کے لیے NaN اقدار کو پُر کرنے کی ضرورت ہوتی ہے، تو نحو فراہم کی جاتی ہے:

تبدیل کریں()
NaN اقدار کے ایک کالم کو تبدیل کرنے کے لیے، فراہم کردہ نحو درج ذیل ہے:

جبکہ، پوری ڈیٹا فریم کی NaN اقدار کو تبدیل کرنے کے لیے، ہمیں درج ذیل نحو کو استعمال کرنا ہوگا:

اس تحریر میں، اب ہم اپنے Pandas DataFrame میں NaN اقدار کو بھرنے کے لیے ان دونوں طریقوں کے عملی نفاذ کو تلاش کریں گے اور سیکھیں گے۔
مثال 1: پانڈا 'فِلنا()' طریقہ استعمال کرتے ہوئے NaN قدریں پُر کریں۔
یہ مثال پانڈا 'DataFrame.fillna()' فنکشن کے اطلاق کو ظاہر کرتی ہے تاکہ دیے گئے ڈیٹا فریم میں NaN ویلیوز کو 0 سے پُر کیا جاسکے۔ آپ یا تو ایک کالم میں گم شدہ اقدار کو پُر کرسکتے ہیں یا آپ انہیں پورے ڈیٹا فریم کے لیے پُر کرسکتے ہیں۔ یہاں، ہم ان دونوں تکنیکوں کو دیکھیں گے۔
ان حکمت عملیوں کو عملی جامہ پہنانے کے لیے، ہمیں پروگرام کے نفاذ کے لیے ایک مناسب پلیٹ فارم حاصل کرنے کی ضرورت ہے۔ لہذا، ہم نے 'اسپائیڈر' ٹول استعمال کرنے کا فیصلہ کیا۔ ہم نے پروگرام میں 'پانڈا' ٹول کٹ کو درآمد کرکے اپنا Python کوڈ شروع کیا ہے کیونکہ ہمیں ڈیٹا فریم کی تعمیر کے ساتھ ساتھ اس ڈیٹا فریم میں موجود گمشدہ اقدار کو پُر کرنے کے لیے پانڈاس فیچر کو استعمال کرنے کی ضرورت ہے۔ 'pd' پورے پروگرام میں 'پانڈا' کے عرف کے طور پر استعمال ہوتا ہے۔
اب، ہمارے پاس پانڈوں کی خصوصیات تک رسائی ہے۔ ہم سب سے پہلے اس کے 'pd.DataFrame()' فنکشن کو اپنا ڈیٹا فریم بنانے کے لیے استعمال کرتے ہیں۔ ہم نے اس طریقہ کو استعمال کیا اور اسے تین کالموں سے شروع کیا۔ ان کالموں کے عنوان 'M1'، 'M2' اور 'M3' ہیں۔ 'M1' کالم میں قدریں '1'، 'کوئی نہیں'، '5'، '9'، اور '3' ہیں۔ 'M2' میں اندراجات 'کوئی نہیں'، '3'، '8'، '4' اور '6' ہیں۔ جبکہ 'M3' ڈیٹا کو '1'، '2'، '3'، '5'، اور 'None' کے طور پر اسٹور کرتا ہے۔ ہمیں ڈیٹا فریم آبجیکٹ کی ضرورت ہوتی ہے جس میں ہم اس ڈیٹا فریم کو ذخیرہ کر سکتے ہیں جب 'pd.DataFrame()' طریقہ کہا جاتا ہے۔ ہم نے ایک 'گمشدہ' ڈیٹا فریم آبجیکٹ بنایا اور اسے اس نتیجہ کے مطابق تفویض کیا جو ہمیں 'pd.DataFrame()' فنکشن سے ملا ہے۔ اس کے بعد، ہم نے Python کا 'print()' طریقہ استعمال کیا تاکہ Python کنسول پر ڈیٹا فریم ڈسپلے کیا جا سکے۔
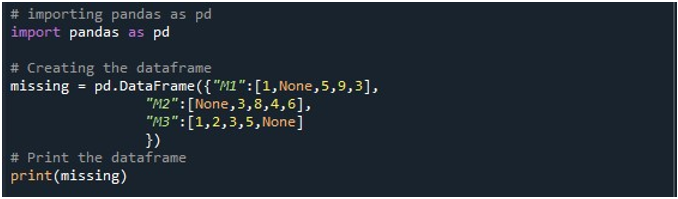
جب ہم کوڈ کا یہ حصہ چلاتے ہیں تو ٹرمینل پر تین کالموں والا ڈیٹا فریم دیکھا جا سکتا ہے۔ یہاں، ہم مشاہدہ کر سکتے ہیں کہ تینوں کالموں میں صفر کی قدریں موجود ہیں۔
ہم نے پانڈاس 'fillna()' فنکشن کو لاگو کرنے کے لیے کچھ null ویلیوز کے ساتھ ڈیٹا فریم بنایا ہے تاکہ 0 سے گم شدہ ویلیوز کو پُر کیا جا سکے۔ آئیے سیکھتے ہیں کہ ہم اسے کیسے کر سکتے ہیں۔
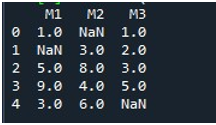
ڈیٹا فریم کو ظاہر کرنے کے بعد، ہم نے پانڈاس 'فلنا()' فنکشن کو شروع کیا۔ یہاں، ہم ایک کالم میں گم شدہ اقدار کو بھرنا سیکھیں گے۔ اس کے لیے نحو پہلے ہی ٹیوٹوریل کے آغاز میں ذکر ہو چکا ہے۔ ہم نے ڈیٹا فریم کا نام فراہم کیا اور مخصوص کالم کا عنوان '.fillna()' فنکشن کے ساتھ بیان کیا۔ اس طریقہ کار کے قوسین کے درمیان، ہم نے وہ قدر فراہم کی ہے جو خالی جگہوں پر رکھی جائے گی۔ ڈیٹا فریم کا نام 'غائب' ہے اور جو کالم ہم نے یہاں منتخب کیا ہے وہ 'M2' ہے۔ 'fillna()' کے منحنی خطوط وحدانی کے درمیان فراہم کردہ قدر '0' ہے۔ آخر میں، ہم نے اپ ڈیٹ شدہ ڈیٹا فریم کو دیکھنے کے لیے 'print()' فنکشن کو بلایا۔

یہاں، آپ دیکھ سکتے ہیں کہ ڈیٹا فریم کے 'M2' کالم میں اب کوئی گم شدہ ویلیو نہیں ہے کیونکہ NaN ویلیو 0 سے بھری ہوئی ہے۔
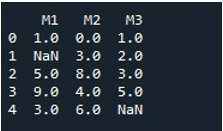
اسی طریقہ سے پورے ڈیٹا فریم کے لیے NaN ویلیوز کو بھرنے کے لیے، ہم نے 'fillna()' کہا۔ یہ کافی آسان ہے۔ ہم نے ڈیٹا فریم کا نام 'fillna()' فنکشن کے ساتھ فراہم کیا اور قوسین کے درمیان فنکشن ویلیو '0' تفویض کیا۔ آخر میں، 'print()' فنکشن نے ہمیں بھرا ہوا ڈیٹا فریم دکھایا۔

اس سے ہمیں ایک ڈیٹا فریم ملتا ہے جس میں کوئی NaN ویلیو نہیں ہے کیونکہ تمام ویلیوز اب 0 سے بھری ہوئی ہیں۔
مثال 2: پانڈا 'Replace()' طریقہ استعمال کرتے ہوئے NaN قدریں پُر کریں۔
مضمون کا یہ حصہ ڈیٹا فریم میں NaN اقدار کو بھرنے کا ایک اور طریقہ دکھاتا ہے۔ ہم ایک کالم اور ایک مکمل ڈیٹا فریم میں ویلیو کو بھرنے کے لیے پانڈوں کے 'replace()' فنکشن کا استعمال کریں گے۔
ہم 'Spyder' ٹول میں کوڈ لکھنا شروع کرتے ہیں۔ سب سے پہلے، ہم نے مطلوبہ لائبریریاں درآمد کیں۔ یہاں، ہم نے پانڈاس لائبریری کو لوڈ کیا تاکہ پائتھون پروگرام کو پانڈا طریقوں کو استعمال کرنے کے قابل بنایا جا سکے۔ دوسری لائبریری جو ہم نے لوڈ کی ہے وہ ہے NumPy اور عرف اسے 'np'۔ NumPy گمشدہ ڈیٹا کو 'replace()' طریقہ سے ہینڈل کرتا ہے۔
پھر، ہم نے ایک ڈیٹا فریم بنایا جس میں تین کالم ہیں - 'سکرو'، 'کیل' اور 'ڈرل'۔ ہر کالم میں قدریں بالترتیب دی گئی ہیں۔ 'سکرو' کالم میں '112'، '234'، 'کوئی نہیں'، اور '650' ویلیوز ہیں۔ 'نیل' کالم میں '123'، '145'، 'کوئی نہیں' اور '711' ہیں۔ آخر میں، 'ڈرل' کالم میں '312'، 'کوئی نہیں'، '500'، اور 'کوئی نہیں' کی قدریں ہیں۔ ڈیٹا فریم کو 'ٹول' ڈیٹا فریم آبجیکٹ میں محفوظ کیا جاتا ہے اور 'پرنٹ()' طریقہ استعمال کرتے ہوئے دکھایا جاتا ہے۔
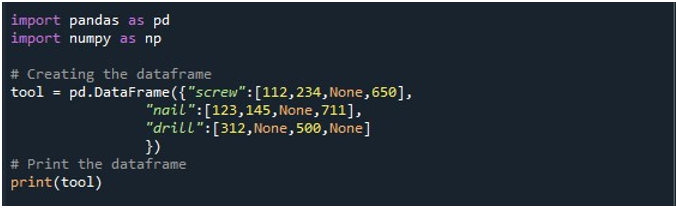
ریکارڈ میں چار NaN اقدار کے ساتھ ایک ڈیٹا فریم درج ذیل آؤٹ پٹ امیج میں دیکھا جا سکتا ہے۔
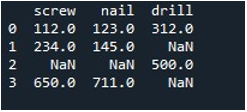
اب، ہم DataFrame کے ایک کالم میں null ویلیوز کو بھرنے کے لیے Pandas 'replace()' طریقہ استعمال کرتے ہیں۔ کام کے لیے، ہم نے 'replace()' فنکشن کو استعمال کیا۔ ہم نے ڈیٹا فریم کا نام 'ٹول' اور کالم 'سکرو' کو '.replace()' طریقہ کے ساتھ فراہم کیا۔ اس کے منحنی خطوط وحدانی کے درمیان، ہم ڈیٹا فریم میں 'np.nan' اندراجات کے لیے '0' کی قدر مقرر کرتے ہیں۔ آؤٹ پٹ کو ظاہر کرنے کے لیے 'پرنٹ()' طریقہ استعمال کیا جاتا ہے۔

نتیجہ خیز ڈیٹا فریم ہمیں پہلا کالم دکھاتا ہے جس میں NaN اندراجات کو 'سکرو' کالم میں 0 سے تبدیل کیا گیا ہے۔
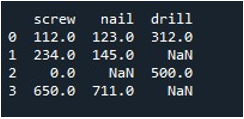
اب، ہم پورے ڈیٹا فریم میں اقدار کو بھرنا سیکھیں گے۔ ہم نے ڈیٹا فریم کے نام کے ساتھ 'replace()' طریقہ کو کہا اور وہ قدر فراہم کی جسے ہم np.nan اندراجات سے تبدیل کرنا چاہتے ہیں۔ آخر میں، ہم نے اپ ڈیٹ کردہ ڈیٹا فریم کو 'print()' فنکشن کے ساتھ پرنٹ کیا۔

یہ ہمیں بغیر کسی گمشدہ ریکارڈ کے نتیجہ خیز ڈیٹا فریم فراہم کرتا ہے۔
نتیجہ
ڈیٹا فریم میں گمشدہ اندراجات سے نمٹنا ایک بنیادی چیز ہے اور پیچیدگی کو کم کرنے اور ڈیٹا کے تجزیہ کے عمل میں ڈیٹا کو بے دلی سے ہینڈل کرنے کے لیے ایک ضروری ضرورت ہے۔ پانڈاس ہمیں اس مسئلے سے نمٹنے کے لیے چند اختیارات فراہم کرتے ہیں۔ ہم اس گائیڈ میں دو کارآمد حکمت عملی لائے ہیں۔ ہم نے 'Spyder' ٹول کی مدد سے دونوں تکنیکوں کو عملی جامہ پہنایا ہے تاکہ نمونے کے کوڈز کو عمل میں لایا جا سکے تاکہ چیزوں کو آپ کے لیے قدرے قابل فہم اور آسان بنایا جا سکے۔ ان افعال کا علم حاصل کرنا آپ کی پانڈوں کی مہارت کو تیز کرے گا۔