پانڈاس سیٹ_آپشن کا طریقہ
آج، ہم دیکھیں گے کہ 'pd.set_option()' فنکشن کو اپنے اسپائیڈر ٹول میں پیش کرتے وقت پانڈاس ڈیٹا فریم میں موجود تمام کالموں کو ڈسپلے کرنے کے لیے کیسے استعمال کیا جائے۔ 'pd.set_option()' استعمال کرنے کے لیے، ہم دیے گئے نحو کی پیروی کرتے ہیں:

آئیے Python پروگرام کے عملی نفاذ کی مدد سے تصور کو سیکھنا شروع کریں۔
مثال: تمام کالموں کو ظاہر کرنے کے لیے پانڈاس سیٹ_آپشن کا طریقہ استعمال کرنا
یہ مظاہرہ پانڈاس 'set_option()' کو استعمال کرکے ڈیٹا فریم میں تمام کالموں کو ظاہر کرنے کے لیے ایک گائیڈ ہے۔ ہم اس ازگر کے طریقہ کار کے نفاذ کے لیے ہر قدم کی تفصیلات واضح کریں گے۔
Python اسکرپٹ کے عملی نفاذ کے لیے سب سے پہلی ضرورت یہ ہے کہ آپ اپنے پروگرام پر عمل کرنے کے لیے بہترین ٹول تلاش کریں۔ ہم نے اپنی مثال کے لیے جو ٹول استعمال کیا ہے وہ ہے 'اسپائیڈر' ٹول۔ ہم نے ٹول لانچ کیا اور Python اسکرپٹ پر کام کرنا شروع کیا۔
کوڈ کے ساتھ شروع کرتے ہوئے، ہمیں ابتدائی طور پر ضروری لائبریریوں کو درآمد کرنے کی ضرورت ہے جن کی ہمیں اس پروگرام میں ضرورت ہے۔ پہلی لائبریری جسے ہم نے اپنی Python فائل میں لوڈ کیا وہ پانڈاس لائبریری ہے کیونکہ ہم یہاں جو فنکشن استعمال کرتے ہیں وہ پانڈوں کے ذریعہ فراہم کیے گئے ہیں۔ ہم نے اس لائبریری کا نام 'pd' رکھا ہے۔ دوسری لائبریری جسے ہم نے لوڈ کیا وہ NumPy لائبریری ہے۔ NumPy (Numerical Python) ایک عددی کمپیوٹنگ پیکیج ہے جو Python پروگرامنگ پر تیار کیا گیا ہے۔ کوڈ کا Import NumPy سیکشن Python کو NumPy ماڈیول کو آپ کی موجودہ Python فائل میں ضم کرنے کی ہدایت کرتا ہے۔ اسکرپٹ کا 'بطور np' حصہ پھر Python کو NumPy کو 'np' مخفف تفویض کرنے کی ہدایت کرتا ہے۔ یہ آپ کو NumPy کے بجائے 'np.function_name' درج کرکے NumPy طریقوں کو استعمال کرنے کے قابل بناتا ہے۔
اب، ہم مرکزی کوڈ کے ساتھ شروع کرتے ہیں۔ ہمارے پروگرام کی سب سے اہم اور بنیادی ضرورت پانڈاس ڈیٹا فریم ہے۔ لہذا، ہم اس میں موجود تمام کالموں کو ظاہر کرتے ہیں۔ اب، یہ مکمل طور پر آپ پر منحصر ہے کہ آیا آپ مخصوص اقدار کے ساتھ ڈیٹا فریم بنانا چاہتے ہیں یا اگر آپ کو CSV فائل درآمد کرنے کی ضرورت ہے۔ اس مثال کے لیے ہم نے جس چیز کا انتخاب کیا ہے وہ NaN اقدار کے ساتھ ڈیٹا فریم بنانا ہے۔ ہم نے ڈیٹا فریم بنانے کے لیے 'pd.DataFrame()' طریقہ استعمال کیا۔ یہاں، ہم نے دو پیرامیٹرز فراہم کیے ہیں - 'انڈیکس' اور 'کالم'۔ 'انڈیکس' دلیل سے مراد قطاریں ہیں جس کا مطلب ہے کہ ہم ڈیٹا فریم کے لیے قطاریں ترتیب دیتے ہیں۔
ہم نے 'انڈیکس' پیرامیٹر اور NumPy فنکشن 'np.arange() کو '6' کی قدر کی گنتی کے ساتھ تفویض کیا ہے۔ یہ ڈیٹا فریم کے لیے چھ قطاریں تیار کرتا ہے۔ یہ تمام اندراجات کو NaN اقدار کے ساتھ بھرتا ہے کیونکہ ہم نے اسے کوئی قدر فراہم نہیں کی ہے۔ 'کالم' دلیل، جیسا کہ نام بتاتا ہے، ڈیٹا فریم کے لیے کالم سیٹ کرنے کے لیے استعمال ہوتا ہے۔ اسے کالموں کے لیے '25' ویلیو گنتی کے ساتھ 'np.arange()' فنکشن بھی تفویض کیا گیا ہے۔ اس طرح، یہ ڈیٹا فریم کے لیے 25 کالم بناتا ہے۔
نتیجتاً، جب ہم 'pd.DataFrame()' فنکشن کو کال کرتے ہیں، تو ہمارے پاس ڈیٹا فریم ہوتا ہے جس میں 25 کالم اور 6 قطاریں خالی ویلیو سے بھری ہوتی ہیں۔ اس ڈیٹا فریم کو محفوظ رکھنے کی ضرورت کے لیے، ہمیں ایک ڈیٹا فریم آبجیکٹ بنانے کی ضرورت ہے جو اس کے مواد کو محفوظ کرے۔ لہذا، ہم نے ڈیٹا فریم آبجیکٹ 'رینڈم' بنایا اور اسے وہ نتیجہ تفویض کیا جو ہمیں 'pd.DataFrame()' طریقہ سے حاصل ہوتا ہے۔ اب، آپ یقینی طور پر ڈیٹا فریم کو تیار ہوتے دیکھنا چاہتے ہیں۔ Python ہمیں اسکرین پر آؤٹ پٹ دیکھنے کا طریقہ فراہم کرتا ہے جو کہ 'print()' فنکشن ہے۔ ہم نے ڈیٹا فریم آبجیکٹ 'رینڈم' کو اس کے پیرامیٹر کے طور پر پاس کرکے اس طریقہ کو استعمال کیا۔
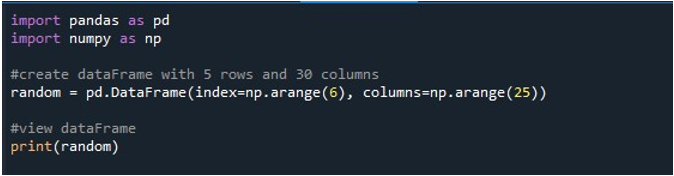
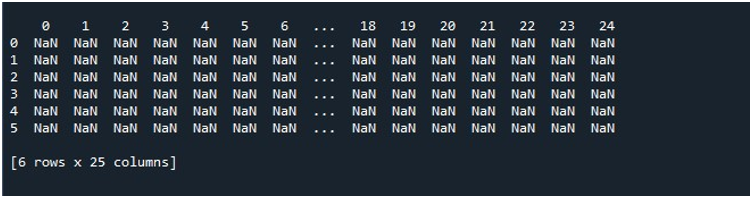
جب ہم اس کوڈ کے ٹکڑوں پر عمل کرتے ہیں، تو ہمیں ٹرمینل پر ظاہر ہونے والی NaN اقدار کے ساتھ اپنا ڈیٹا فریم ملتا ہے۔ یہاں، ہم مشاہدہ کر سکتے ہیں کہ پہلے کالم میں سے کچھ اور آخر سے صرف چند ہی نظر آتے ہیں۔ درمیان کے تمام کالم تراشے گئے ہیں۔ پہلے سے طے شدہ طور پر، یہ کچھ قطاروں اور کالموں کو چھپاتا ہے تاکہ صارف کے لیے بھاری ڈیٹا سیٹس دکھا کر مایوسی پیدا نہ ہو۔
یہاں تک کہ آپ پانڈوں کے 'len()' فنکشن کا استعمال کرکے ڈیٹا فریم میں کل کالموں کی تعداد بھی چیک کرسکتے ہیں۔ اپنے 'Spyder' ٹول کے کنسول پر 'len()' فنکشن لکھیں۔ DataFrame کا نام اس کے قوسین کے درمیان '.columns' خاصیت کے ساتھ لکھیں۔ یہ ہمیں آپ کے ڈیٹا فریم میں کالموں کی کل لمبائی واپس کرتا ہے۔

یہ ہمارے ڈیٹا فریم کی لمبائی لوٹاتا ہے جو 25 ہے۔
اب، اگلا اور بنیادی کام آؤٹ پٹ کو ظاہر کرنے کے لیے ڈیفالٹ آپشن کو تبدیل کرنا ہے۔ ایسے حالات ہوسکتے ہیں جہاں آپ ٹرمینل پر پورا ڈیٹا فریم دیکھنا چاہتے ہیں۔ پہلے سے طے شدہ اقدار کی وجہ سے، بہت سے اندراجات کٹ جاتے ہیں جو صارف کے لیے مایوسی کا باعث بنتے ہیں۔ آپ یہاں سیکھیں گے کہ اس مسئلے پر کیسے قابو پایا جائے۔ پانڈا ہمیں ڈیفالٹ ڈسپلے سیٹنگز کو تبدیل کرنے کے لیے 'pd.set_option()' فنکشن فراہم کرتا ہے۔ کنسول پر ڈیٹا فریم ڈسپلے کرنے کے فوراً بعد، ہم 'pd.set_option()' طریقہ استعمال کرتے ہیں۔ ہم اس فنکشن کے قوسین کے درمیان پیرامیٹر کی وضاحت کرتے ہیں جسے ہمیں ڈیٹا فریم کے تمام کالم ڈسپلے کرنے کے لیے استعمال کرنے کی ضرورت ہے۔
یہاں، ہم نے اپنے ڈیٹا فریم میں زیادہ سے زیادہ کالم دکھانے کے لیے 'display.max_columns' کا استعمال کیا۔ ہم اس پیرامیٹر کی قدر کی بھی وضاحت کر سکتے ہیں، یعنی زیادہ سے زیادہ کالم جو آپ ڈسپلے کرنا چاہتے ہیں۔ دوسری طرف، ہم نے 'display.max_columns' کو 'None' پر سیٹ کیا جو ڈیٹا فریم کے تمام کالموں کو زیادہ سے زیادہ لمبائی کے ساتھ دکھاتا ہے۔ آخر میں، ہم نے ٹرمینل پر نظر آنے والے تمام کالموں کے ساتھ نتیجہ خیز ڈیٹا فریم کو ظاہر کرنے کے لیے 'print()' فنکشن کا استعمال کیا۔
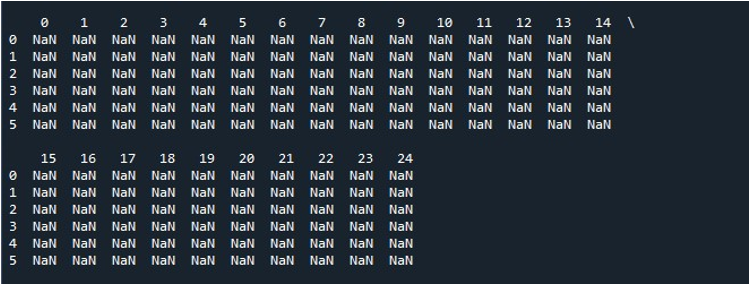
جب ہم 'Spyder' ٹول پر 'Run file' کے آپشن کو مارتے ہیں، تو ہم ڈیٹا فریم کی نمائش دیکھ سکتے ہیں۔ اس ڈیٹا فریم میں چھ قطاریں ہیں اور اس کے پاس موجود کالموں کی تعداد 25 ہے۔ کوئی کالم ایسا نہیں ہے جسے چھوٹا کیا گیا ہو کیونکہ کالم کی زیادہ سے زیادہ لمبائی کے ساتھ 'pd.set_option()' فنکشن اب فعال ہے۔
ہم ڈسپلے آپشن کو بھی ری سیٹ کر سکتے ہیں کیونکہ ایک بار جب ہم ڈسپلے کی لمبائی کو زیادہ سے زیادہ پر سیٹ کر دیتے ہیں، تو یہ ڈیٹا فریمز کو اس مخصوص Python فائل کے اندر موجود تمام کالموں کے ساتھ دکھاتا رہتا ہے۔ اس کے لیے، ہم پانڈا 'pd.reset_option()' استعمال کرتے ہیں۔ ہم اس فنکشن کی درخواست کرتے ہیں اور اس فنکشن کے پیرامیٹر کے طور پر 'display.max_columns' فراہم کرتے ہیں۔

اس سے ہمیں فراہم کردہ ڈیٹا فریم کے لیے ابتدائی ڈسپلے سیٹنگ مل جاتی ہے۔
نتیجہ
ایک بڑے ڈیٹاسیٹ کے ساتھ ٹرمینل پر مکمل آؤٹ پٹ دیکھنے کے لیے بعض اوقات جب ٹول کی ڈیفالٹ سیٹنگز صارف کی ضروریات کے برعکس آتی ہیں تو ہمیں پریشانی کا سامنا کرنا پڑتا ہے۔ اس دھچکے کو دور کرنے کے لیے، پانڈاس ہمیں 'pd.set_option()' طریقہ فراہم کرتا ہے۔ اس سیکھنے کی گائیڈ میں، ہم نے آپ کو اس طریقہ کار اور اسے استعمال کرنے کی ضرورت سے متعارف کرایا ہے۔ ہم نے اس موضوع کو عملی طور پر مرتب اور عمل میں لائے ہوئے Python نمونہ کوڈز کے ساتھ دکھایا۔ ہم نے 'اسپائیڈر' پر کی گئی مثال کے نتائج کو پیش کیا۔ ہم نے وضاحت کی کہ ڈیٹا فریم کے تمام کالموں کو کنسول پر ڈیفالٹ سیٹنگز کو تبدیل کرنے کے ساتھ ساتھ تمام سیٹنگز کو ابتدائی پر ری سیٹ کرنے کا طریقہ۔ ماڈیول کے عملی نفاذ پر پوری توجہ مرکوز کرنا آپ کو اس قابل بناتا ہے کہ جب بھی آپ کو اس طرح کی پریشانی کا سامنا ہو تو اسے استعمال کر سکیں۔