ٹیبلر ڈیٹا کا تجزیہ کرنے کے لیے ڈیٹا سائنسدانوں کے ذریعہ آج کل استعمال کیے جانے والے سب سے مشہور ٹولز میں پانڈہ ہیں۔ ٹیبلر مواد سے نمٹنے کے لیے، یہ ایک تیز اور زیادہ موثر API پیش کرتا ہے۔ جب بھی ہم تجزیہ کے دوران ڈیٹا فریم دیکھتے ہیں، پانڈا خود بخود مختلف ڈسپلے رویوں کو ڈیفالٹ ویلیوز پر سیٹ کرتا ہے۔ ان ڈسپلے رویوں میں یہ شامل ہے کہ کتنی قطاریں اور کالم دکھائے جائیں، ہر ڈیٹا فریم میں فلوٹس کی درستگی، کالم کے سائز وغیرہ۔ ضروریات پر منحصر ہے، ہمیں کبھی کبھار ان ڈیفالٹس میں ترمیم کرنے کی ضرورت پڑ سکتی ہے۔ ڈیفالٹ رویے کو تبدیل کرنے کے لیے پانڈوں کے پاس مختلف طریقے ہیں۔ پانڈوں کی 'اختیارات' کی خصوصیت کا فائدہ اٹھاتے ہوئے ہمیں اس طرز عمل کو تبدیل کرنے کے قابل بنایا۔
پانڈا زیادہ سے زیادہ قطاریں ڈسپلے کریں۔
جب بھی آپ ایک بہت بڑا ڈیٹا فریم پرنٹ کرنے کی کوشش کریں گے جس میں پہلے سے طے شدہ حد سے زیادہ قطاریں اور کالم ہوں گے، آؤٹ پٹ کو تراش لیا جائے گا۔ ڈیٹا فریم میں تمام قطاریں دکھانے کے لیے، آپ اس ٹیوٹوریل میں پانڈوں کے ڈسپلے کے اختیارات میں ترمیم کرنے کا طریقہ سیکھیں گے۔ پانڈا بطور ڈیفالٹ کالموں اور قطاروں کی تعداد پر ایک حد لگاتے ہیں جو اس کی نمائش کرتا ہے۔ اگرچہ یہ مواد پڑھنے کے لیے مفید ہو سکتا ہے، لیکن اگر آپ کو جو معلومات دیکھنے کی ضرورت ہے وہ نہیں دکھائی جاتی ہے تو یہ اکثر مایوسی کا باعث بنتا ہے۔ یہاں، ہم ڈیٹا فریم کے تمام کالموں کو ظاہر کرنے کے لیے ان کے نحو کے ساتھ نیچے دیئے گئے طریقے استعمال کریں گے۔
to_string()

سیٹ_آپشن()

option_context()

ہم فراہم کردہ ڈیٹا فریم میں زیادہ سے زیادہ قطاریں ظاہر کرنے کے لیے عملی نفاذ کے ساتھ ان تمام طریقوں کا استعمال سیکھیں گے۔
مثال نمبر 1: پانڈوں کو سٹرنگ () طریقہ استعمال کرنا
یہ مظاہرہ ہمیں پانڈا 'to_string()' طریقہ استعمال کرکے ٹرمینل پر ڈیٹا فریم میں زیادہ سے زیادہ قطاریں دکھانا سکھائے گا۔
نمونے کے پروگراموں کی تالیف اور اس پر عمل درآمد کے لیے، ہم نے 'Spyder' ٹول کا انتخاب کیا ہے۔ اس گائیڈ میں، ہم اس ٹول کو اپنی تمام مثالوں کے نفاذ کے لیے استعمال کریں گے۔ ہم نے python اسکرپٹ لکھنا شروع کرنے کے لیے 'Spyder' ٹول لانچ کیا ہے۔ کوڈ کے ساتھ شروع کرتے ہوئے، ہمیں پہلے ضروری لائبریریوں کو اپنی ازگر کی فائل میں لوڈ کرنے کی ضرورت ہے تاکہ ہمیں اس کی خصوصیات کو استعمال کرنے کی اجازت ہو۔ ہمیں یہاں جس ماڈیول لائبریری کی ضرورت ہے وہ ہے 'پانڈا'۔ لہذا، ہم نے اسے اپنی python فائل میں درآمد کیا اور اسے 'pd' کے نام سے منسوب کیا۔
چونکہ اس مضمون کا بنیادی کام ڈیٹا فریم کی زیادہ سے زیادہ قطاروں کو ظاہر کرنا ہے، ہمیں پہلے ڈیٹا فریم کی ضرورت ہے۔ اب یہ آپ پر منحصر ہے کہ آپ ڈیٹا فریم بنانا پسند کرتے ہیں یا CSV فائل درآمد کرنا چاہتے ہیں۔ ہم نے ایک نمونہ CSV فائل درآمد کی ہے۔ python پروگرام میں CSV فائل پڑھنے کے لیے، ہم نے pandas 'pd.read_csv()' فنکشن استعمال کیا ہے۔ اس فنکشن کے قوسین کے درمیان، ہم نے CSV فائل فراہم کی ہے جسے ہم ڈسپلے کو پڑھنا چاہتے ہیں، جو کہ 'industry.csv' ہے۔ فراہم کردہ CSV فائل کو پڑھنے سے پیدا ہونے والے آؤٹ پٹ کو ذخیرہ کرنے کے لیے ہم نے ایک متغیر 'df' بنایا ہے۔ پھر، ہم نے ڈیٹا فریم کو ظاہر کرنے کے لیے 'print()' طریقہ استعمال کیا۔
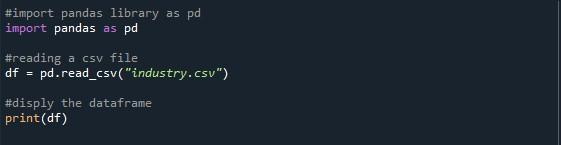
جب ہم اس python پروگرام کو 'Run file' آپشن کو دبا کر چلاتے ہیں تو کنسول پر ایک ڈیٹا فریم کی نمائش ہوتی ہے۔ آپ مشاہدہ کر سکتے ہیں کہ نیچے دیئے گئے نتیجے میں 43 قطاریں ہیں لیکن صرف دس دکھائی دیتی ہیں۔ اس کی وجہ یہ ہے کہ پانڈاس لائبریری کی ڈیفالٹ ویلیو صرف 10 قطاریں ہیں۔
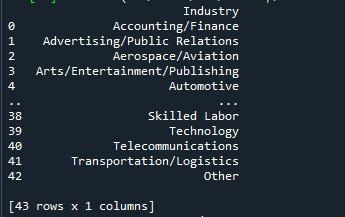
ہم یہاں تمام قطاروں کو دکھانے کے لیے پانڈا طریقہ 'to_string' استعمال کریں گے۔ ڈیٹا فریم سے زیادہ سے زیادہ قطاریں دکھانے کا سب سے سیدھا طریقہ اس تکنیک کے ساتھ ہے۔ تاہم، چونکہ یہ پورے ڈیٹا فریم کو ایک ہی تار میں بدل دیتا ہے، اس لیے بہت بڑے ڈیٹاسیٹس (لاکھوں میں) کے لیے اس کی سفارش نہیں کی جاتی ہے۔ اس کے باوجود، یہ ڈیٹاسیٹس کے لیے مؤثر طریقے سے کام کرتا ہے جو ہزاروں کی لمبائی میں ہیں۔
ہم نے 'to_string()' فنکشن کے لیے اوپر فراہم کردہ نحو کی پیروی کی ہے۔ ہم نے اپنے ڈیٹا فریم کے نام کے ساتھ صرف 'to_string()' طریقہ استعمال کیا۔ پھر ہم نے اس طریقہ کو 'print()' فنکشن میں رکھا تاکہ اسے کال کرنے پر ظاہر کیا جا سکے۔

آؤٹ پٹ اسنیپ شاٹ ہمیں ڈیٹا فریم دکھاتا ہے جس میں تمام قطاریں ٹرمینل پر ظاہر ہوتی ہیں۔
مثال نمبر 2: پانڈا سیٹ_آپشن کا طریقہ استعمال کرنا
دوسرا طریقہ جس کی ہم اس گائیڈ میں مشق کریں گے وہ ہے پانڈا 'set_option()' فراہم کردہ ڈیٹا فریم کی زیادہ سے زیادہ قطاریں ظاہر کرنے کے لیے۔
python فائل میں، ہم نے اوپر بیان کردہ فنکشن تک رسائی کے لیے پانڈاس لائبریری کو درآمد کیا ہے۔ ہم نے فراہم کردہ CSV فائل کو پڑھنے کے لیے پانڈا 'pd.read_csv()' کا استعمال کیا ہے۔ ہم نے CSV فائل کے نام کے ساتھ 'pd.read_CSV()' فنکشن کو استعمال کیا جسے ہم اس کے قوسین کے درمیان استعمال کرنا چاہتے ہیں جو کہ 'Sampledata.csv' ہے۔ CSV فائل درآمد کرتے وقت، Python پروگرام کی موجودہ ورکنگ ڈائرکٹری کو ذہن میں رکھیں۔ آپ کی CSV فائل کو اسی ڈائرکٹری میں رکھا جانا چاہیے۔ دوسری صورت میں، آپ کو ایک ایرر میسج ملے گا 'فائل نہیں ملی'۔ ہم نے CSV فائل سے ڈیٹا فریم کو ذخیرہ کرنے کے لیے ایک متغیر 'نمونہ' بنایا ہے۔ اس ڈیٹا فریم کو دکھانے کے لیے ہم نے 'print()' طریقہ کہا۔
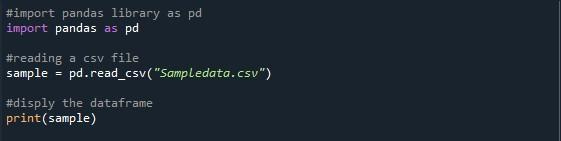
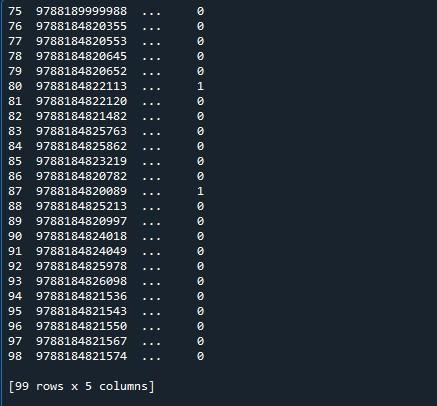
یہاں، ہمارے پاس آؤٹ پٹ ہے جہاں صرف دس قطاریں دکھائی دیتی ہیں۔ اشارہ کردہ قطاروں کی زیادہ سے زیادہ تعداد 99 ہے۔ پہلی 5 اور آخری پانچ قطاروں کے درمیان باقی تمام قطاریں کٹی ہوئی ہیں۔

اس ڈیٹا فریم کے لیے زیادہ سے زیادہ 99 قطاریں دکھانے کے لیے، ہم پانڈا ماڈیول کا 'set_option()' فنکشن استعمال کریں گے۔ پانڈاس آپریٹنگ سسٹم کے ساتھ آتے ہیں جو آپ کو رویے اور ڈسپلے کو تبدیل کرنے کی اجازت دیتا ہے۔ یہ طریقہ ہمیں اس قابل بناتا ہے کہ ہم ڈسپلے کو کٹے ہوئے فریم کی بجائے مکمل ڈیٹا فریم کی نمائش کے لیے سیٹ کریں۔ پانڈا ڈیٹا فریم کی تمام قطاروں کو دکھانے کے لیے فنکشن 'set_ option()' فراہم کرتے ہیں۔
ہم نے 'pd.set_option()' کو استعمال کیا ہے۔ اس فنکشن میں 'display.max_rows' کے پیرامیٹرز ہیں۔ 'display.max_rows' قطاروں کی زیادہ سے زیادہ تعداد کی وضاحت کرتا ہے جو ڈیٹا فریم کو ڈسپلے کرتے وقت دکھائی جائیں گی۔ 'max_rows' کی قدر بطور ڈیفالٹ 10 پر سیٹ ہوتی ہے۔ اگر 'کوئی نہیں' منتخب کیا گیا ہے، تو یہ ڈیٹا فریم میں تمام قطاروں کی نشاندہی کرتا ہے۔ جیسا کہ ہم تمام قطاروں کو ظاہر کرنا چاہتے ہیں، لہذا ہم اسے 'کوئی نہیں' پر سیٹ کرتے ہیں۔ آخر میں، ہم نے ڈیٹا فریم کو زیادہ سے زیادہ قطاروں کے ساتھ ڈسپلے کرنے کے لیے 'print()' فنکشن کا استعمال کیا۔

یہ ذیل میں اسنیپ شاٹ میں فراہم کردہ نتیجہ برآمد کرتا ہے۔
مثال نمبر 3: پانڈاس آپشن_سیاق و سباق () طریقہ استعمال کرنا
آخری طریقہ جس پر ہم یہاں بات کر رہے ہیں وہ ہے 'option_context()' تمام ڈیٹا فریم کی قطاروں کو ظاہر کرنے کے لیے۔ اس کے لیے ہم نے پانڈاس پیکج کو python فائل میں امپورٹ کیا اور کوڈ لکھنا شروع کیا۔ ہم نے اپنی مخصوص کردہ CSV فائل کو پڑھنے کے لیے 'pd.read_csv()' فنکشن استعمال کیا ہے۔ ہم نے مخصوص CSV فائل سے ڈیٹا فریم کو ذخیرہ کرنے کے لیے ایک متغیر 'ڈالٹا' بنایا ہے۔ پھر، ہم نے ڈیٹا فریم کو 'print()' طریقہ سے پرنٹ کیا۔
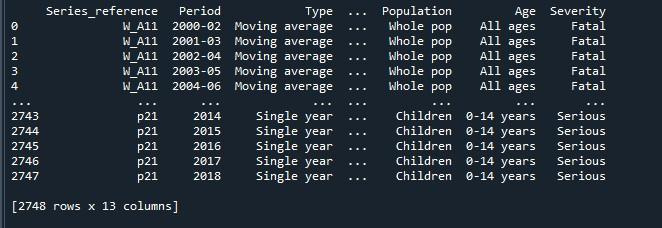
مندرجہ بالا کوڈ پر عمل کرنے سے جو نتیجہ ہم نے حاصل کیا ہے وہ ہمیں کٹی ہوئی قطاروں کے ساتھ ڈیٹا فریم دکھاتا ہے۔
اب ہم اس ڈیٹا فریم پر پانڈا 'pd.option_context()' کا اطلاق کریں گے۔ یہ فنکشن 'set_option()' سے مماثل ہے۔ دونوں طریقوں کے درمیان فرق صرف یہ ہے کہ 'set_option()' سیٹنگز کو مستقل طور پر تبدیل کرتا ہے، جبکہ 'option _context()' نے انہیں اپنے دائرہ کار میں تبدیل کر دیا ہے۔ یہ طریقہ پیرامیٹر کے طور پر display.max قطاروں کو بھی لیتا ہے، جسے ہم ڈیٹا فریم کی تمام قطاروں کو رینڈر کرنے کے لیے 'کوئی نہیں' پر سیٹ کرتے ہیں۔ اس فنکشن کو شروع کرنے کے بعد، ہم نے اسے صرف 'print()' طریقہ کے ذریعے ظاہر کیا۔

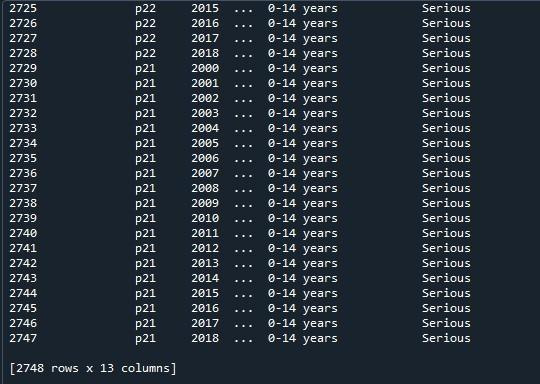
یہاں، ہم مکمل ڈیٹا فریم کو اس کی زیادہ سے زیادہ قطاروں کے ساتھ دیکھ سکتے ہیں جو 2747 ہیں۔
نتیجہ
یہ مضمون پانڈوں کے ڈسپلے کے اختیارات پر مرکوز ہے۔ ہمیں کبھی کبھی ٹرمینل پر مکمل ڈیٹا فریم دیکھنے کی ضرورت پڑ سکتی ہے۔ پانڈے اس مقصد کے لیے ہمیں مختلف قسم کے اختیارات دیتے ہیں۔ اس گائیڈ میں، ہم نے ان میں سے تین حکمت عملیوں کو استعمال کیا ہے۔ پہلی مثال 'to_string()' طریقہ استعمال کرنے پر مبنی تھی۔ ہماری دوسری مثال ہمیں 'set_option()' کو لاگو کرنا سکھاتی ہے جب کہ آخری مثال 'option_context()' طریقہ پر عمل درآمد کرتی ہے۔ ان تمام تکنیکوں کا مظاہرہ آپ کو ان متبادل طریقوں سے واقف کرانے کے لیے کیا گیا ہے جو پانڈا ہمیں مطلوبہ نتائج حاصل کرنے کے لیے فراہم کرتے ہیں۔