یہ گائیڈ LangChain میں گفتگو کے علم کے گراف کو استعمال کرنے کے عمل کی وضاحت کرے گا۔
LangChain میں گفتگو کے علم کا گراف کیسے استعمال کریں؟
دی گفتگو کے جی میموری لائبریری کا استعمال میموری کو دوبارہ بنانے کے لیے کیا جا سکتا ہے جو بات چیت کے سیاق و سباق کو حاصل کرنے کے لیے استعمال کی جا سکتی ہے۔ LangChain میں گفتگو کے علم کے گراف کو استعمال کرنے کا طریقہ سیکھنے کے لیے، بس درج کردہ مراحل سے گزریں:
مرحلہ 1: ماڈیولز انسٹال کریں۔
سب سے پہلے، LangChain ماڈیول کو انسٹال کر کے گفتگو کے علم کے گراف کو استعمال کرنے کے عمل کے ساتھ شروع کریں:
pip انسٹال langchain
اوپن اے آئی ماڈیول انسٹال کریں جو بڑی زبان کے ماڈلز بنانے کے لیے اپنی لائبریریوں کو حاصل کرنے کے لیے پائپ کمانڈ کا استعمال کرتے ہوئے انسٹال کیا جا سکتا ہے:
پائپ انسٹال اوپنائی
ابھی، ماحول قائم کریں OpenAI API کلید کا استعمال کرتے ہوئے جو اس کے اکاؤنٹ سے تیار کیا جا سکتا ہے:
درآمد تم
درآمد گیٹ پاس
تم . تقریباً [ 'OPENAI_API_KEY' ] = گیٹ پاس . گیٹ پاس ( 'اوپن اے آئی API کلید:' )
مرحلہ 2: LLMs کے ساتھ میموری کا استعمال
ماڈیولز انسٹال ہونے کے بعد، LangChain ماڈیول سے مطلوبہ لائبریریوں کو درآمد کرکے LLM کے ساتھ میموری کا استعمال شروع کریں:
سے langchain یاداشت درآمد گفتگو کے جی میموریسے langchain ایل ایم ایس درآمد اوپن اے آئی
OpenAI() طریقہ استعمال کرتے ہوئے LLM بنائیں اور اس کا استعمال کرتے ہوئے میموری کو کنفیگر کریں۔ گفتگو کے جی میموری () طریقہ۔ اس کے بعد، اس ڈیٹا پر ماڈل کو تربیت دینے کے لیے ان کے متعلقہ جواب کے ساتھ متعدد ان پٹ کا استعمال کرتے ہوئے پرامپٹ ٹیمپلیٹس کو محفوظ کریں:
ایل ایل ایم = اوپن اے آئی ( درجہ حرارت = 0 )یاداشت = گفتگو کے جی میموری ( ایل ایل ایم = ایل ایل ایم )
یاداشت. سیویٹ_سیاق و سباق ( { 'ان پٹ' : 'جان کو ہیلو کہو' } , { 'آؤٹ پٹ' : 'جان! کون' } )
یاداشت. سیویٹ_سیاق و سباق ( { 'ان پٹ' : 'وہ دوست ہے' } , { 'آؤٹ پٹ' : 'ضرور' } )
لوڈ کرکے میموری کی جانچ کریں۔ میموری_متغیر () مذکورہ ڈیٹا سے متعلق استفسار کا استعمال کرتے ہوئے طریقہ:
یاداشت. load_memory_variables ( { 'ان پٹ' : 'جان کون ہے' } ) 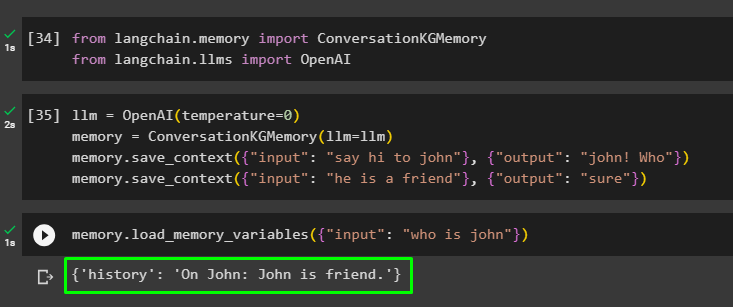
کے ساتھ ConversationKGMemory() طریقہ استعمال کرکے میموری کو ترتیب دیں۔ واپسی_پیغامات ان پٹ کی تاریخ بھی حاصل کرنے کے لیے دلیل:
یاداشت = گفتگو کے جی میموری ( ایل ایل ایم = ایل ایل ایم , واپسی_پیغامات = سچ ہے۔ )یاداشت. سیویٹ_سیاق و سباق ( { 'ان پٹ' : 'جان کو ہیلو کہو' } , { 'آؤٹ پٹ' : 'جان! کون' } )
یاداشت. سیویٹ_سیاق و سباق ( { 'ان پٹ' : 'وہ دوست ہے' } , { 'آؤٹ پٹ' : 'ضرور' } )
استفسار کی صورت میں ان پٹ دلیل کو اس کی قدر کے ساتھ فراہم کرکے بس میموری کی جانچ کریں:
یاداشت. load_memory_variables ( { 'ان پٹ' : 'جان کون ہے' } ) 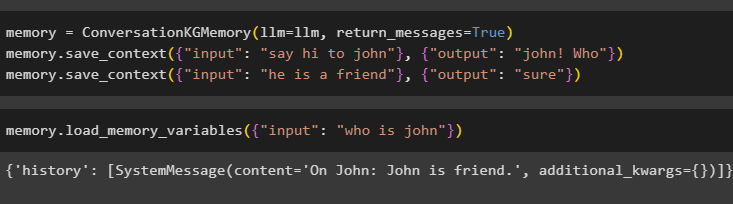
اب، وہ سوال پوچھ کر میموری کی جانچ کریں جس کا تربیتی ڈیٹا میں ذکر نہیں ہے، اور ماڈل کو جواب کے بارے میں کوئی اندازہ نہیں ہے:
یاداشت. حاصل_کرنٹ_اینٹیٹیز ( 'جان کا پسندیدہ رنگ کیا ہے' )کا استعمال کرتے ہیں حاصل_علم_تین () پہلے پوچھے گئے سوال کا جواب دے کر طریقہ:
یاداشت. حاصل_علم_تین ( 'اس کا پسندیدہ رنگ سرخ ہے' ) 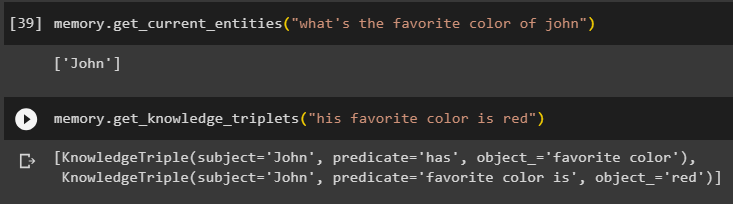
مرحلہ 3: سلسلہ میں میموری کا استعمال
اگلا مرحلہ OpenAI() طریقہ استعمال کرتے ہوئے LLM ماڈل بنانے کے لیے زنجیروں کے ساتھ گفتگو کی میموری کا استعمال کرتا ہے۔ اس کے بعد، بات چیت کے ڈھانچے کا استعمال کرتے ہوئے پرامپٹ ٹیمپلیٹ کو ترتیب دیں اور ماڈل کے ذریعہ آؤٹ پٹ حاصل کرنے کے دوران متن ظاہر کیا جائے گا:
ایل ایل ایم = اوپن اے آئی ( درجہ حرارت = 0 )سے langchain اشارہ کرتا ہے . فوری طور پر درآمد PromptTemplate
سے langchain زنجیریں درآمد گفتگو کا سلسلہ
سانچے = '''یہ انسان اور مشین کے درمیان تعامل کا سانچہ ہے۔
سسٹم ایک AI ماڈل ہے جو متعدد پہلوؤں کے بارے میں بات کر سکتا ہے یا معلومات نکال سکتا ہے۔
اگر اسے سوال سمجھ نہیں آتا یا اس کا جواب نہیں ہے، تو یہ صرف اتنا کہتا ہے۔
سسٹم ایکسٹریکٹ ڈیٹا کو 'مخصوص' سیکشن میں محفوظ کرتا ہے اور فریب نہیں دیتا
مخصوص:
{تاریخ}
گفتگو:
انسانی: {input}
AI:'''
# پرامپٹس فراہم کرنے اور AI سسٹم سے جواب حاصل کرنے کے لیے ٹیمپلیٹ یا ڈھانچے کو ترتیب دیں۔
فوری طور پر = PromptTemplate ( input_variables = [ 'تاریخ' , 'ان پٹ' ] , سانچے = سانچے )
بات چیت_کے ساتھ_کلوگرام = گفتگو کا سلسلہ (
ایل ایل ایم = ایل ایل ایم , لفظی = سچ ہے۔ , فوری طور پر = فوری طور پر , یاداشت = گفتگو کے جی میموری ( ایل ایل ایم = ایل ایل ایم )
)
ایک بار ماڈل بن جانے کے بعد، صرف کال کریں۔ بات چیت_کے ساتھ_کلوگرام صارف کی طرف سے پوچھے گئے استفسار کے ساتھ predict() طریقہ استعمال کرتے ہوئے ماڈل:
بات چیت_کے ساتھ_کلوگرام پیشن گوئی ( ان پٹ = 'کیا ہو رہا ہے؟' ) 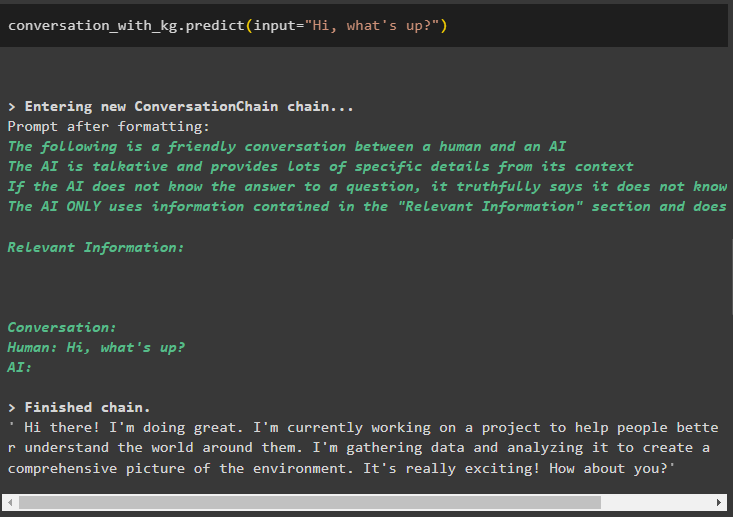
اب، طریقہ کار کے لیے ان پٹ دلیل کے طور پر معلومات دے کر گفتگو کی میموری کا استعمال کرتے ہوئے ماڈل کو تربیت دیں:
بات چیت_کے ساتھ_کلوگرام پیشن گوئی (ان پٹ = 'میرا نام جیمز ہے اور میں ول کی مدد کر رہا ہوں، وہ ایک انجینئر ہے'
)
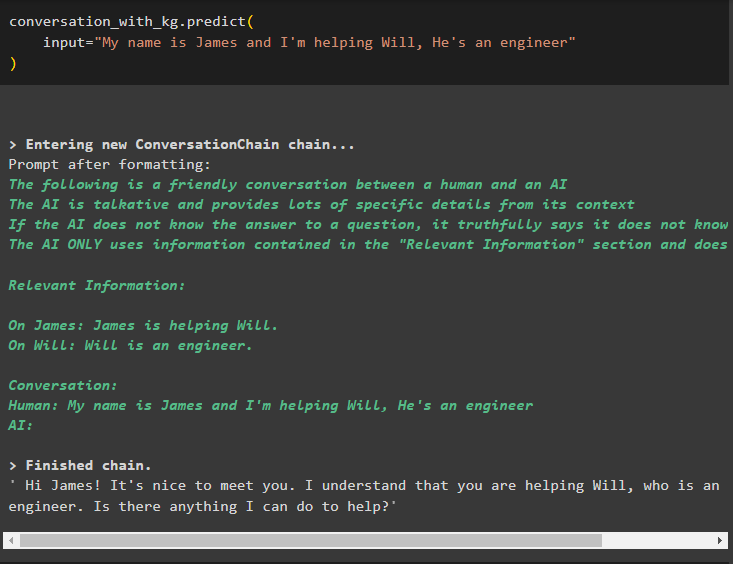
ڈیٹا سے معلومات نکالنے کے لیے سوالات پوچھ کر ماڈل کی جانچ کرنے کا یہ وقت ہے:
بات چیت_کے ساتھ_کلوگرام پیشن گوئی ( ان پٹ = 'کون ہے' ) 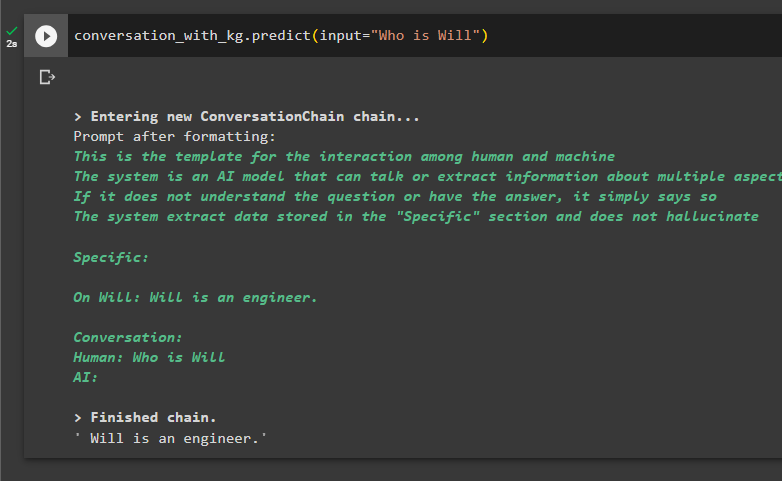
یہ سب کچھ LangChain میں گفتگو کے علم کے گراف کو استعمال کرنے کے بارے میں ہے۔
نتیجہ
LangChain میں گفتگو کے علم کا گراف استعمال کرنے کے لیے، ConversationKGMemory() طریقہ استعمال کرنے کے لیے لائبریریوں کو درآمد کرنے کے لیے ماڈیولز یا فریم ورک انسٹال کریں۔ اس کے بعد، زنجیریں بنانے کے لیے میموری کا استعمال کرتے ہوئے ماڈل بنائیں اور ترتیب میں فراہم کردہ تربیتی ڈیٹا سے معلومات نکالیں۔ اس گائیڈ نے LangChain میں گفتگو کے علم کے گراف کو استعمال کرنے کے عمل کی وضاحت کی ہے۔